import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix, f1_score, precision_score, \
recall_score, roc_auc_score
from sklearn.inspection import permutation_importance
import matplotlib.pyplot as plt26 Feature Engineering (Titanic Dataset)
One of the best ways to improve model performance is feature engineering.
When feature engineering, we create additional columns using - domain knowledge - combinations and interactions of features in the dataset - additional lookups (e.g. the travel time for a patient from the clinic they are visiting rather than just learning from the postcode combinations)
Let’s see if we can improve performance on the titanic dataset with a little feature engineering.
We’re going to import the raw data rather than the preprocessed data we’ve used in some cases as we want to make use of some of the additional features available in this dataset.
try:
data = pd.read_csv("data/raw_data.csv")
except FileNotFoundError:
# Download raw data:
address = 'https://raw.githubusercontent.com/MichaelAllen1966/' + \
'1804_python_healthcare/master/titanic/data/train.csv'
data = pd.read_csv(address)
# Create a data subfolder if one does not already exist
import os
data_directory ='./data/'
if not os.path.exists(data_directory):
os.makedirs(data_directory)
# Save data
data.to_csv(data_directory + 'raw_data.csv', index=False)
data| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
26.1 Binary features - Simple Conditions
First, let’s make a feature that reflects whether the passenger is under 16.
data['Under18'] = np.where(data['Age'] < 18 , 1, 0)
data.head(10)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 0 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q | 0 |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S | 0 |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S | 1 |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S | 0 |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C | 1 |
26.2 Binary Features - Using a combination of other columns
Next, let’s make a column that reflects whether the passenger is travelling alone or with any family.
data['TravellingWithFamily'] = np.where(
(data['SibSp'] + data['Parch']) >= 1, # Condition
1, # Value if True
0 # Value if False
)
data.head(10)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 0 | 1 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 0 | 1 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 0 |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q | 0 | 0 |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S | 0 | 0 |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S | 1 | 1 |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S | 0 | 1 |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C | 1 | 1 |
26.3 Features from Complex String Patterns - Regular Expressions
Now let’s extract groups of titles from the name column.
We could extract each individual title, but if there are a lot, this could lead to a very high number of columns when we go to one-hot encode our data. What we want to mainly explore from titles is whether people were noble, general populace, or young.
The easiest way to do this here is to use something called Regular Expressions.
Regular expressions allow us to match varying strings, like telephone numbers that may have different spacings or numbers of digits. We won’t be using them to their full potential here! But they have the benefit of being usable with the contains method to allow us to pass a series of strings we would like to match with.
First, let’s import the re library.
import reBefore turning this into a column, let’s explore how we would match strings for a couple of categories of passengers.
Let’s start with looking at upper-class titles.
Here, we’re going to filter to rows where the ‘name’ column contains any one of
- Col.
- Capt.
- Don.
- Countess.
- Dr.
- Lady.
- Sir.
- Major.
- Rev.
- Jonkheer.
- Dona.
We want to ensure we look out for a . after these as in this dataset, a . is consistently used after a title. This is handy for us!
However, in regex, a . has a special meaning - so we need to pass a \ before it to tell the regular expression we’re looking for an actual full stop.
We then use the pipe | to denote or.
data[data['Name'].str.contains(r"Col\.|Capt\.|Don\.|Countess\.|Dr\.|Lady\.|Sir\.|Major\.|Rev\.|Jonkheer\.|Dona\.")]| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | 31 | 0 | 1 | Uruchurtu, Don. Manuel E | male | 40.0 | 0 | 0 | PC 17601 | 27.7208 | NaN | C | 0 | 0 |
| 149 | 150 | 0 | 2 | Byles, Rev. Thomas Roussel Davids | male | 42.0 | 0 | 0 | 244310 | 13.0000 | NaN | S | 0 | 0 |
| 150 | 151 | 0 | 2 | Bateman, Rev. Robert James | male | 51.0 | 0 | 0 | S.O.P. 1166 | 12.5250 | NaN | S | 0 | 0 |
| 245 | 246 | 0 | 1 | Minahan, Dr. William Edward | male | 44.0 | 2 | 0 | 19928 | 90.0000 | C78 | Q | 0 | 1 |
| 249 | 250 | 0 | 2 | Carter, Rev. Ernest Courtenay | male | 54.0 | 1 | 0 | 244252 | 26.0000 | NaN | S | 0 | 1 |
| 317 | 318 | 0 | 2 | Moraweck, Dr. Ernest | male | 54.0 | 0 | 0 | 29011 | 14.0000 | NaN | S | 0 | 0 |
| 398 | 399 | 0 | 2 | Pain, Dr. Alfred | male | 23.0 | 0 | 0 | 244278 | 10.5000 | NaN | S | 0 | 0 |
| 449 | 450 | 1 | 1 | Peuchen, Major. Arthur Godfrey | male | 52.0 | 0 | 0 | 113786 | 30.5000 | C104 | S | 0 | 0 |
| 536 | 537 | 0 | 1 | Butt, Major. Archibald Willingham | male | 45.0 | 0 | 0 | 113050 | 26.5500 | B38 | S | 0 | 0 |
| 556 | 557 | 1 | 1 | Duff Gordon, Lady. (Lucille Christiana Sutherl... | female | 48.0 | 1 | 0 | 11755 | 39.6000 | A16 | C | 0 | 1 |
| 599 | 600 | 1 | 1 | Duff Gordon, Sir. Cosmo Edmund ("Mr Morgan") | male | 49.0 | 1 | 0 | PC 17485 | 56.9292 | A20 | C | 0 | 1 |
| 626 | 627 | 0 | 2 | Kirkland, Rev. Charles Leonard | male | 57.0 | 0 | 0 | 219533 | 12.3500 | NaN | Q | 0 | 0 |
| 632 | 633 | 1 | 1 | Stahelin-Maeglin, Dr. Max | male | 32.0 | 0 | 0 | 13214 | 30.5000 | B50 | C | 0 | 0 |
| 647 | 648 | 1 | 1 | Simonius-Blumer, Col. Oberst Alfons | male | 56.0 | 0 | 0 | 13213 | 35.5000 | A26 | C | 0 | 0 |
| 660 | 661 | 1 | 1 | Frauenthal, Dr. Henry William | male | 50.0 | 2 | 0 | PC 17611 | 133.6500 | NaN | S | 0 | 1 |
| 694 | 695 | 0 | 1 | Weir, Col. John | male | 60.0 | 0 | 0 | 113800 | 26.5500 | NaN | S | 0 | 0 |
| 745 | 746 | 0 | 1 | Crosby, Capt. Edward Gifford | male | 70.0 | 1 | 1 | WE/P 5735 | 71.0000 | B22 | S | 0 | 1 |
| 759 | 760 | 1 | 1 | Rothes, the Countess. of (Lucy Noel Martha Dye... | female | 33.0 | 0 | 0 | 110152 | 86.5000 | B77 | S | 0 | 0 |
| 766 | 767 | 0 | 1 | Brewe, Dr. Arthur Jackson | male | NaN | 0 | 0 | 112379 | 39.6000 | NaN | C | 0 | 0 |
| 796 | 797 | 1 | 1 | Leader, Dr. Alice (Farnham) | female | 49.0 | 0 | 0 | 17465 | 25.9292 | D17 | S | 0 | 0 |
| 822 | 823 | 0 | 1 | Reuchlin, Jonkheer. John George | male | 38.0 | 0 | 0 | 19972 | 0.0000 | NaN | S | 0 | 0 |
| 848 | 849 | 0 | 2 | Harper, Rev. John | male | 28.0 | 0 | 1 | 248727 | 33.0000 | NaN | S | 0 | 1 |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S | 0 | 0 |
Let’s repeat this to look at rows containing other groupings of titles.
What about ‘regular’ class people?
data[data['Name'].str.contains(r"Mrs\.|Mlle\.|Mr\.|Mons\.")]| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 0 | 1 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 0 | 1 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 0 |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 883 | 884 | 0 | 2 | Banfield, Mr. Frederick James | male | 28.0 | 0 | 0 | C.A./SOTON 34068 | 10.5000 | NaN | S | 0 | 0 |
| 884 | 885 | 0 | 3 | Sutehall, Mr. Henry Jr | male | 25.0 | 0 | 0 | SOTON/OQ 392076 | 7.0500 | NaN | S | 0 | 0 |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q | 0 | 1 |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C | 0 | 0 |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q | 0 | 0 |
644 rows × 14 columns
Now let’s look at instances relating to children.
data[data['Name'].str.contains(r"Master\.|Miss\.")]| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 | 0 |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S | 1 | 1 |
| 10 | 11 | 1 | 3 | Sandstrom, Miss. Marguerite Rut | female | 4.0 | 1 | 1 | PP 9549 | 16.7000 | G6 | S | 1 | 1 |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S | 0 | 0 |
| 14 | 15 | 0 | 3 | Vestrom, Miss. Hulda Amanda Adolfina | female | 14.0 | 0 | 0 | 350406 | 7.8542 | NaN | S | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 869 | 870 | 1 | 3 | Johnson, Master. Harold Theodor | male | 4.0 | 1 | 1 | 347742 | 11.1333 | NaN | S | 1 | 1 |
| 875 | 876 | 1 | 3 | Najib, Miss. Adele Kiamie "Jane" | female | 15.0 | 0 | 0 | 2667 | 7.2250 | NaN | C | 1 | 0 |
| 882 | 883 | 0 | 3 | Dahlberg, Miss. Gerda Ulrika | female | 22.0 | 0 | 0 | 7552 | 10.5167 | NaN | S | 0 | 0 |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S | 0 | 0 |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S | 0 | 1 |
222 rows × 14 columns
Let’s put in all of the ones we’ve come up with so far and check we haven’t missed anyone.
We’ve used the ~ operator to filter our dataframe to instances where a match has NOT been found instead.
data[~data['Name'].str.contains(r"Master\.|Miss\.|Mrs\.|Mlle\.|Mr\.|Mons\.|Col\.|Capt\.|Don\.|Countess\.|Dr\.|Lady\.|Sir\.|Major\.|Rev\.|Jonkheer\.|Dona\.")]| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 369 | 370 | 1 | 1 | Aubart, Mme. Leontine Pauline | female | 24.0 | 0 | 0 | PC 17477 | 69.3 | B35 | C | 0 | 0 |
| 443 | 444 | 1 | 2 | Reynaldo, Ms. Encarnacion | female | 28.0 | 0 | 0 | 230434 | 13.0 | NaN | S | 0 | 0 |
It looks like we’ve missed Mme. and Ms. so we’ll make sure to add those into the ‘Regular’ status for our final query.
26.3.1 Creating the column
Now we’ve explored and built our query, we can turn this into our final column.
We’re going to use np.where again - this does get a bit complex with longer queries!
It effectively is structured like a big if-else clause.
np.where(condition, value_if_true, value_if_false)
We nest these by passing additional np.where statements in the value if false position.
This may feel familiar if you’ve had to do a big if clause in Excel!
(note that this would be a lot easier in a newer version of pandas - they released a ‘case_when’ function in v2.2 - those of you used to SQL may be familiar with that sort of thing)
First, let’s just run the statement and see the output.
I’ve added in some extra complexity to look at the ‘age’ column as well for the first two instances.
You may wish to indent your code differently for readability - the indentation won’t have any impact on the functioning here.
np.where(
(data['Name'].str.contains(r"Master\.|Miss\.")) & (data['Age'] <18), "Young",
np.where((data['Name'].str.contains(r"Miss\.")) & (data['Age'] >=18), "Unmarried Woman",
np.where(data['Name'].str.contains(r"Mrs\.|Mlle\.|Mr\.|Mons\."), "Regular",
np.where(data['Name'].str.contains(r"Col\.|Capt\.|Don\.|Countess\.|Dr\.|Lady\.|Sir\.|Major\.|Rev\.|Jonkheer\.|Dona\."), "Upper Class",
"Unknown"
)))
)array(['Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Young', 'Regular', 'Regular', 'Young',
'Unmarried Woman', 'Regular', 'Regular', 'Young', 'Regular',
'Young', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Young', 'Regular', 'Young', 'Regular', 'Regular', 'Regular',
'Unknown', 'Regular', 'Upper Class', 'Regular', 'Unknown',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Young', 'Regular', 'Regular', 'Regular',
'Young', 'Unmarried Woman', 'Regular', 'Regular', 'Unknown',
'Regular', 'Regular', 'Young', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Young',
'Young', 'Regular', 'Unmarried Woman', 'Regular', 'Young',
'Regular', 'Unknown', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Young', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Young', 'Unmarried Woman', 'Regular',
'Regular', 'Unknown', 'Regular', 'Young', 'Regular', 'Regular',
'Regular', 'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Regular', 'Unknown', 'Regular', 'Young', 'Regular',
'Unmarried Woman', 'Young', 'Regular', 'Regular', 'Regular',
'Regular', 'Young', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Young', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Young', 'Regular', 'Upper Class',
'Upper Class', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Young', 'Regular', 'Regular', 'Unknown', 'Regular',
'Regular', 'Regular', 'Regular', 'Young', 'Young', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Young', 'Young',
'Regular', 'Regular', 'Regular', 'Unknown', 'Unmarried Woman',
'Regular', 'Regular', 'Unknown', 'Regular', 'Young', 'Young',
'Young', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Young', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Unknown',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Young', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Unmarried Woman', 'Regular', 'Unmarried Woman',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Unknown', 'Regular',
'Regular', 'Regular', 'Young', 'Regular', 'Unknown', 'Regular',
'Young', 'Regular', 'Regular', 'Unknown', 'Unknown', 'Regular',
'Regular', 'Regular', 'Upper Class', 'Unmarried Woman', 'Regular',
'Regular', 'Upper Class', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Unmarried Woman',
'Unmarried Woman', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Unknown', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Unknown', 'Unmarried Woman', 'Unmarried Woman', 'Regular',
'Young', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Unmarried Woman', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Young',
'Regular', 'Regular', 'Unknown', 'Regular', 'Regular', 'Unknown',
'Regular', 'Young', 'Unknown', 'Regular', 'Regular',
'Unmarried Woman', 'Unmarried Woman', 'Unmarried Woman', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Upper Class',
'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Unmarried Woman',
'Regular', 'Regular', 'Regular', 'Young', 'Unknown', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Young',
'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Unmarried Woman', 'Regular', 'Young',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Unmarried Woman', 'Unmarried Woman', 'Unknown',
'Unknown', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unknown', 'Unknown', 'Regular',
'Regular', 'Regular', 'Regular', 'Young', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Young', 'Regular', 'Regular', 'Regular',
'Regular', 'Young', 'Unmarried Woman', 'Regular', 'Young',
'Regular', 'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Regular', 'Unmarried Woman', 'Regular', 'Upper Class', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Young', 'Regular',
'Unknown', 'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Regular', 'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Young', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Young',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unknown', 'Regular', 'Young', 'Young',
'Regular', 'Young', 'Upper Class', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Young', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Young', 'Young', 'Regular', 'Regular', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Unknown', 'Unmarried Woman', 'Young',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Unmarried Woman',
'Regular', 'Regular', 'Regular', 'Young', 'Regular', 'Regular',
'Regular', 'Unmarried Woman', 'Young', 'Upper Class',
'Unmarried Woman', 'Regular', 'Unmarried Woman', 'Unmarried Woman',
'Young', 'Young', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Young', 'Regular', 'Regular', 'Regular',
'Regular', 'Unmarried Woman', 'Regular', 'Upper Class', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unknown', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unknown', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Upper Class', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Unmarried Woman', 'Regular',
'Regular', 'Young', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Upper Class', 'Unmarried Woman',
'Regular', 'Regular', 'Regular', 'Regular', 'Upper Class',
'Regular', 'Young', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Young', 'Regular',
'Young', 'Regular', 'Regular', 'Upper Class', 'Regular',
'Unmarried Woman', 'Regular', 'Unmarried Woman', 'Regular',
'Unknown', 'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Upper Class', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Young', 'Regular', 'Young',
'Regular', 'Regular', 'Upper Class', 'Regular', 'Regular',
'Unknown', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Unmarried Woman', 'Unknown', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Unmarried Woman',
'Unmarried Woman', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Unknown',
'Regular', 'Unmarried Woman', 'Unmarried Woman', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Unmarried Woman',
'Regular', 'Regular', 'Upper Class', 'Regular', 'Unmarried Woman',
'Regular', 'Regular', 'Young', 'Young', 'Regular', 'Regular',
'Regular', 'Young', 'Regular', 'Regular', 'Regular', 'Upper Class',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Upper Class', 'Unmarried Woman', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Young', 'Regular', 'Regular', 'Young', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unmarried Woman', 'Young',
'Young', 'Regular', 'Regular', 'Regular', 'Unknown', 'Regular',
'Regular', 'Regular', 'Upper Class', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Young', 'Young', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Young', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Upper Class', 'Regular', 'Young', 'Regular', 'Regular',
'Young', 'Regular', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Regular', 'Unmarried Woman', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Unmarried Woman',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Upper Class', 'Regular', 'Young', 'Regular', 'Young', 'Young',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Regular', 'Regular', 'Regular', 'Unknown', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Young', 'Regular',
'Regular', 'Regular', 'Regular', 'Regular', 'Regular',
'Unmarried Woman', 'Regular', 'Regular', 'Regular', 'Upper Class',
'Unmarried Woman', 'Unknown', 'Regular', 'Regular'], dtype='<U15')We can see it outputs a numpy array - effectively a big list - with the matched statement for each row.
Now let’s assign that to a column in our dataframe and take a look at it in context.
data['Title'] = np.where(
(data['Name'].str.contains(r"Master\.|Miss\.")) & (data['Age'] <18), "Young",
np.where((data['Name'].str.contains(r"Miss\.")) & (data['Age'] >=18), "Unmarried Woman",
np.where(data['Name'].str.contains(r"Mrs\.|Mlle\.|Mr\.|Mons\."), "Regular",
np.where(data['Name'].str.contains(r"Col\.|Capt\.|Don\.|Countess\.|Dr\.|Lady\.|Sir\.|Major\.|Rev\.|Jonkheer\.|Dona\."), "Upper Class",
"Unknown"
))))
# Select just the name, age and title columns
# Return a random sample of 15 rows
data[['Name', 'Age', 'Title']].sample(15)| Name | Age | Title | |
|---|---|---|---|
| 691 | Karun, Miss. Manca | 4.0 | Young |
| 194 | Brown, Mrs. James Joseph (Margaret Tobin) | 44.0 | Regular |
| 719 | Johnson, Mr. Malkolm Joackim | 33.0 | Regular |
| 805 | Johansson, Mr. Karl Johan | 31.0 | Regular |
| 125 | Nicola-Yarred, Master. Elias | 12.0 | Young |
| 441 | Hampe, Mr. Leon | 20.0 | Regular |
| 225 | Berglund, Mr. Karl Ivar Sven | 22.0 | Regular |
| 354 | Yousif, Mr. Wazli | NaN | Regular |
| 260 | Smith, Mr. Thomas | NaN | Regular |
| 409 | Lefebre, Miss. Ida | NaN | Unknown |
| 444 | Johannesen-Bratthammer, Mr. Bernt | NaN | Regular |
| 560 | Morrow, Mr. Thomas Rowan | NaN | Regular |
| 739 | Nankoff, Mr. Minko | NaN | Regular |
| 175 | Klasen, Mr. Klas Albin | 18.0 | Regular |
| 289 | Connolly, Miss. Kate | 22.0 | Unmarried Woman |
Finally, let’s see how many people fall into each category.
data['Title'].value_counts()Regular 644
Unmarried Woman 95
Young 87
Unknown 42
Upper Class 23
Name: Title, dtype: int6426.4 Feature from Simple String Patterns - Getting the Deck from the Cabin Number
Let’s also work out which deck they were staying on based on the cabin number.
Let’s first look at a single cabin number from our dataframe.
data['Cabin'][1]'C85'On further inspection, it turns out that the first letter of the cabin string is always the deck number.
We can just pull back the .str attribute in each case and pull out the 1st letter (in position 0 - remember Python counts from 0).
data['Deck'] = data['Cabin'].str[0]
data.head(10)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | Title | Deck | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 | Regular | NaN |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 0 | 1 | Regular | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 | 0 | Unmarried Woman | NaN |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 0 | 1 | Regular | C |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 0 | Regular | NaN |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q | 0 | 0 | Regular | NaN |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S | 0 | 0 | Regular | E |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S | 1 | 1 | Young | NaN |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S | 0 | 1 | Regular | NaN |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C | 1 | 1 | Regular | NaN |
Let’s see how many people were on each deck, and how many didn’t have a cabin number.
data['Deck'].value_counts(dropna=False)NaN 687
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
Name: Deck, dtype: int6426.4.1 Numeric Columns - Adding Values - Family Size
Let’s calculate the family size by adding two numeric columns together.
data['FamilySize'] = data['SibSp'] + data['Parch']
data.head(10)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Under18 | TravellingWithFamily | Title | Deck | FamilySize | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 | Regular | NaN | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 0 | 1 | Regular | C | 1 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 | 0 | Unmarried Woman | NaN | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 0 | 1 | Regular | C | 1 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 0 | Regular | NaN | 0 |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q | 0 | 0 | Regular | NaN | 0 |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S | 0 | 0 | Regular | E | 0 |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S | 1 | 1 | Young | NaN | 4 |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S | 0 | 1 | Regular | NaN | 2 |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C | 1 | 1 | Regular | NaN | 1 |
26.6 Indicating Missing Values
We will be one-hot encoding the ‘embarked’ column. It can be helpful to provide an extra column to indcate when the relevant column contains a missing value.
data['Embarked_Missing'] = data['Embarked'].isna().astype('int')
data['Embarked_Missing'].value_counts()0 889
1 2
Name: Embarked_Missing, dtype: int64In a later step, we are going to impute values where existing values are missing.
It can help to have features indicating that a value was missing and replaced.
data['Age_Imputed'] = data['Age'].isna().astype('int')
data['Age_Imputed'].value_counts()0 714
1 177
Name: Age_Imputed, dtype: int64Let’s remind ourselves what the dataframe looks like at this stage.
data| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | ... | Embarked | Under18 | TravellingWithFamily | Title | Deck | FamilySize | NumPeopleTicketShared | FarePerPerson | Embarked_Missing | Age_Imputed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | ... | S | 0 | 1 | Regular | NaN | 1 | 1 | 7.2500 | 0 | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | ... | C | 0 | 1 | Regular | C | 1 | 1 | 71.2833 | 0 | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | ... | S | 0 | 0 | Unmarried Woman | NaN | 0 | 1 | 7.9250 | 0 | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | ... | S | 0 | 1 | Regular | C | 1 | 2 | 26.5500 | 0 | 0 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | ... | S | 0 | 0 | Regular | NaN | 0 | 1 | 8.0500 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | ... | S | 0 | 0 | Upper Class | NaN | 0 | 1 | 13.0000 | 0 | 0 |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | ... | S | 0 | 0 | Unmarried Woman | B | 0 | 1 | 30.0000 | 0 | 0 |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | ... | S | 0 | 1 | Unknown | NaN | 3 | 2 | 11.7250 | 0 | 1 |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | ... | C | 0 | 0 | Regular | C | 0 | 1 | 30.0000 | 0 | 0 |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | ... | Q | 0 | 0 | Regular | NaN | 0 | 1 | 7.7500 | 0 | 0 |
891 rows × 21 columns
27 Comparing performance
Finally, we need to do the remaining data preparation steps to make this data usable by machine learning models.
###############################
# Replace unclear data values #
###############################
embarked_lookup = {
'S': 'Southampton',
'C': 'Cherbourg',
'Q': 'Queenstown'
}
data['Embarked'] = data['Embarked'].apply(lambda row_value: embarked_lookup.get(row_value))
#######################
# One hot encoding #
#######################
one_hot_embarked = pd.get_dummies(data['Embarked'], prefix='Embarked').astype('int')
# Drop the column as it is now encoded
data = data.drop('Embarked', axis = 1)
# Join the encoded df
data = data.join(one_hot_embarked)
one_hot_title = pd.get_dummies(data['Title'], prefix='Title').astype('int')
# Drop the column as it is now encoded
data = data.drop('Title', axis = 1)
# Join the encoded df
data = data.join(one_hot_title)
one_hot_deck = pd.get_dummies(data['Deck'], prefix='Deck').astype('int')
# Drop the column as it is now encoded
data = data.drop('Deck', axis = 1)
# Join the encoded df
data = data.join(one_hot_deck)
#######################
# Dichotomous columns #
#######################
data['Sex'].replace('male', 1, inplace=True)
data['Sex'].replace('female', 0, inplace=True)
data = data.rename(columns={'Sex': 'IsMale'})
#####################################
# Tidying up remaining column names #
#####################################
data = data.drop(columns=['Name', 'Ticket', 'Cabin'])
data.head()| PassengerId | Survived | Pclass | IsMale | Age | SibSp | Parch | Fare | Under18 | TravellingWithFamily | ... | Title_Upper Class | Title_Young | Deck_A | Deck_B | Deck_C | Deck_D | Deck_E | Deck_F | Deck_G | Deck_T | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 1 | 22.0 | 1 | 0 | 7.2500 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 1 | 1 | 0 | 38.0 | 1 | 0 | 71.2833 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 3 | 1 | 3 | 0 | 26.0 | 0 | 0 | 7.9250 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 1 | 1 | 0 | 35.0 | 1 | 0 | 53.1000 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 5 | 0 | 3 | 1 | 35.0 | 0 | 0 | 8.0500 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 31 columns
27.0.1 Original Dataset Performance
data.drop('PassengerId', inplace=True, axis=1)
X = data.drop('Survived',axis=1) # X = all 'data' except the 'survived' column
y = data['Survived'] # y = 'survived' column from 'data'
X_train, X_validate, y_train, y_validate = train_test_split(X, y, test_size=0.2, random_state=42)print(f"Training Dataset Samples: {len(X_train)}")
print(f"Validation Dataset Samples: {len(X_validate)}")Training Dataset Samples: 712
Validation Dataset Samples: 179def impute_missing_df(df, impute_type="median"):
imputed_df = df.copy()
imputed_df.values[:] = SimpleImputer(missing_values=np.nan, strategy=impute_type).fit_transform(df)
return imputed_df
X_train = impute_missing_df(X_train, impute_type="median")
X_validate = impute_missing_df(X_validate, impute_type="median")def fit_assess(name="XGBoost",
X_train=X_train, X_validate=X_validate,
y_train=y_train, y_validate=y_validate,
model=XGBClassifier(random_state=42)
):
model.fit(X_train, y_train)
y_pred_train = model.predict(X_train)
y_pred_val = model.predict(X_validate)
tn, fp, fn, tp = confusion_matrix(y_validate, y_pred_val, labels=[0, 1]).ravel()
return (pd.DataFrame({
'Accuracy (training)': np.mean(y_pred_train == y_train),
'Accuracy (validation)': np.mean(y_pred_val == y_validate),
'Precision (validation)': precision_score(y_validate, y_pred_val, average='macro'),
'Recall (validation)': recall_score(y_validate, y_pred_val, average='macro'),
"AUC": roc_auc_score(y_validate, y_pred_val),
"f1": f1_score(y_validate, y_pred_val, average='macro'),
"FP": fp,
"FN": fn
}, index=[name]
).round(3), model)X_train.columnsIndex(['Pclass', 'IsMale', 'Age', 'SibSp', 'Parch', 'Fare', 'Under18',
'TravellingWithFamily', 'FamilySize', 'NumPeopleTicketShared',
'FarePerPerson', 'Embarked_Missing', 'Age_Imputed',
'Embarked_Cherbourg', 'Embarked_Queenstown', 'Embarked_Southampton',
'Title_Regular', 'Title_Unknown', 'Title_Unmarried Woman',
'Title_Upper Class', 'Title_Young', 'Deck_A', 'Deck_B', 'Deck_C',
'Deck_D', 'Deck_E', 'Deck_F', 'Deck_G', 'Deck_T'],
dtype='object')original_columns = [
'Pclass', 'IsMale', 'Age', 'SibSp', 'Parch', 'Fare',
'Embarked_Missing', 'Age_Imputed',
'Embarked_Cherbourg', 'Embarked_Queenstown', 'Embarked_Southampton'
]
before_engineering = fit_assess(
X_train=X_train[original_columns],
X_validate=X_validate[original_columns],
name="Without Feature Engineering"
)
results_df = before_engineering[0]
results_df| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|
| Without Feature Engineering | 0.969 | 0.804 | 0.799 | 0.795 | 0.795 | 0.797 | 16 | 19 |
result_pfi = permutation_importance(
before_engineering[1], X_validate[original_columns], y_validate,
n_repeats=10, random_state=42, n_jobs=2
)
feature_importances_pfi = pd.Series(result_pfi.importances_mean, index=X_train[original_columns].columns.tolist())
fig, ax = plt.subplots(figsize=(15,10))
feature_importances_pfi.plot.barh(yerr=result_pfi.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_xlabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()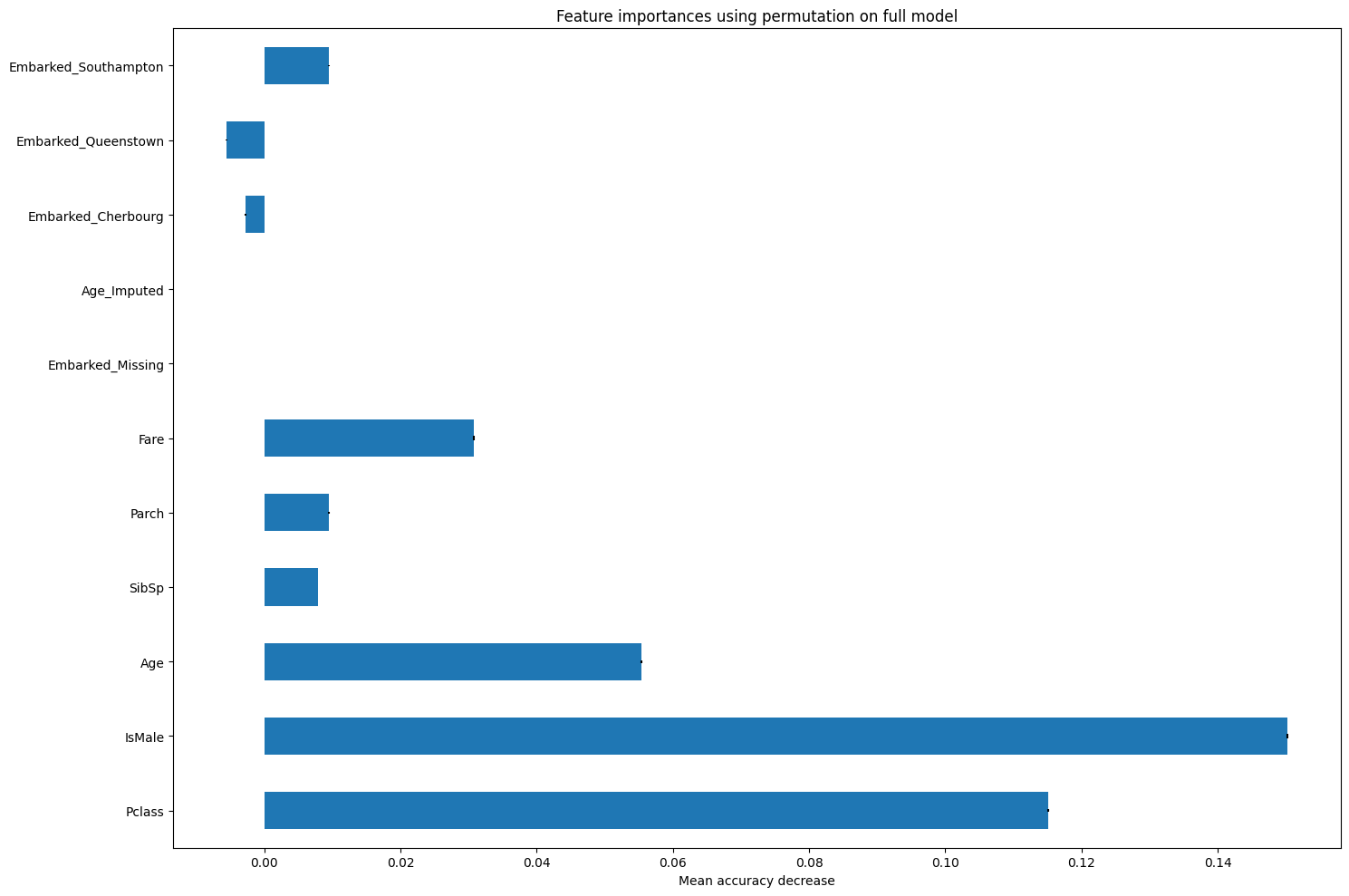
selected_columns = ['Pclass', 'IsMale', 'Age', 'SibSp', 'Parch', 'Fare']
before_engineering_2 = fit_assess(
X_train=X_train[selected_columns],
X_validate=X_validate[selected_columns],
name="Before Feature Engineering - subset of columns"
)
results_df = pd.concat(
[results_df,
before_engineering_2[0]
]
)
results_df| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|
| Without Feature Engineering | 0.969 | 0.804 | 0.799 | 0.795 | 0.795 | 0.797 | 16 | 19 |
| Before Feature Engineering - subset of columns | 0.963 | 0.810 | 0.806 | 0.800 | 0.800 | 0.803 | 15 | 19 |
27.1 Performance with engineered features
after_engineering = fit_assess(
X_train=X_train,
X_validate=X_validate,
name="After Feature Engineering"
)
results_df = pd.concat([
results_df,
after_engineering[0]
])
results_df| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|
| Without Feature Engineering | 0.969 | 0.804 | 0.799 | 0.795 | 0.795 | 0.797 | 16 | 19 |
| Before Feature Engineering - subset of columns | 0.963 | 0.810 | 0.806 | 0.800 | 0.800 | 0.803 | 15 | 19 |
| After Feature Engineering | 0.975 | 0.782 | 0.776 | 0.774 | 0.774 | 0.775 | 19 | 20 |
result_pfi = permutation_importance(
after_engineering[1], X_validate, y_validate,
n_repeats=10, random_state=42, n_jobs=2
)
feature_importances_pfi = pd.Series(result_pfi.importances_mean, index=X_train.columns.tolist())
fig, ax = plt.subplots(figsize=(15,10))
feature_importances_pfi.plot.barh(yerr=result_pfi.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_xlabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()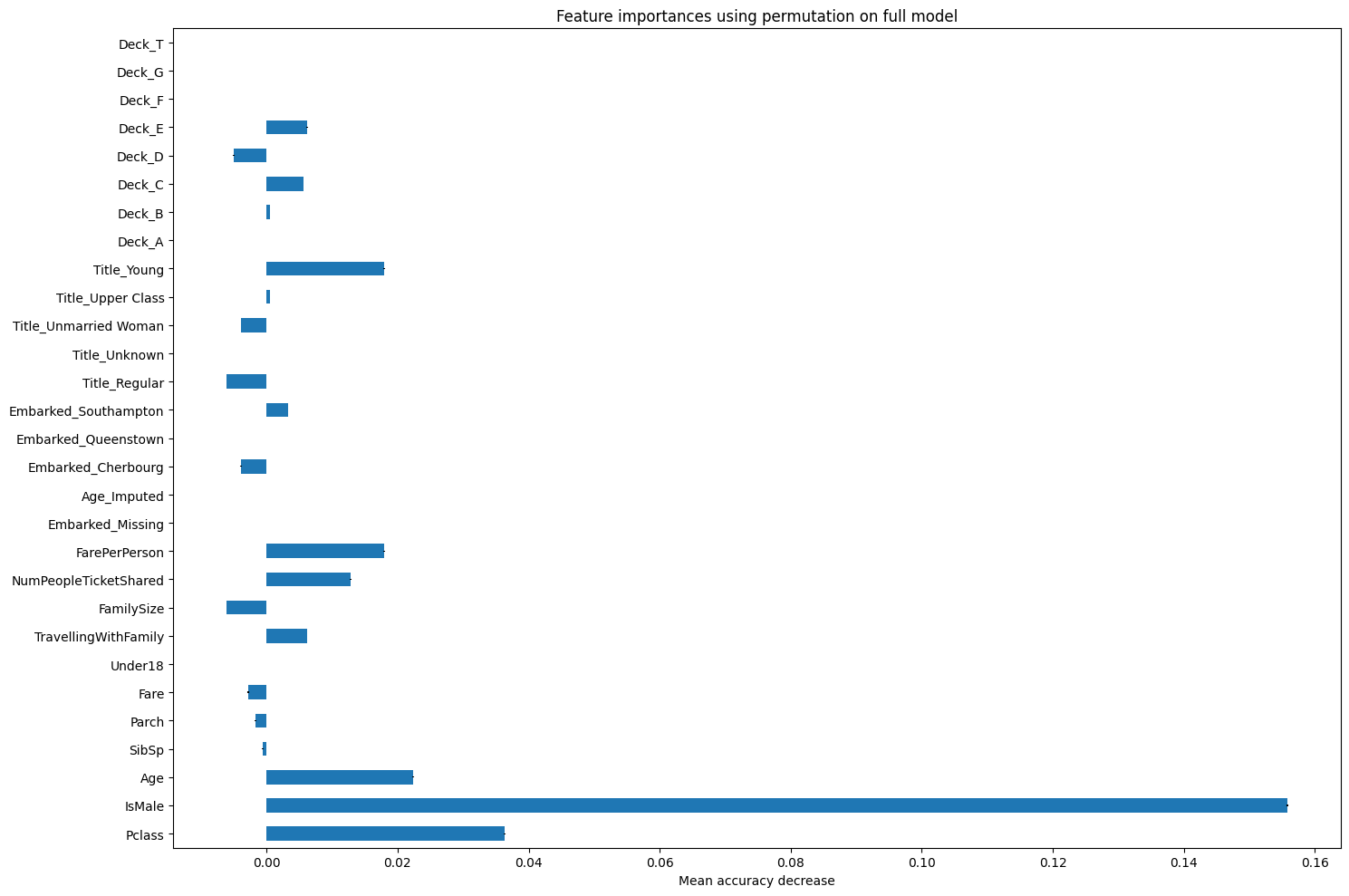
Let’s rerun with just some of the features that are the most impactful.
selected_columns = ['Pclass', 'IsMale', 'Age', 'TravellingWithFamily', 'NumPeopleTicketShared', 'FarePerPerson']
after_engineering_2 = fit_assess(
X_train=X_train[selected_columns],
X_validate=X_validate[selected_columns],
name="After Feature Engineering - subset of columns"
)
results_df = pd.concat(
[results_df,
after_engineering_2[0]
]
)
results_df| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|
| Without Feature Engineering | 0.969 | 0.804 | 0.799 | 0.795 | 0.795 | 0.797 | 16 | 19 |
| Before Feature Engineering - subset of columns | 0.963 | 0.810 | 0.806 | 0.800 | 0.800 | 0.803 | 15 | 19 |
| After Feature Engineering | 0.975 | 0.782 | 0.776 | 0.774 | 0.774 | 0.775 | 19 | 20 |
| After Feature Engineering - subset of columns | 0.969 | 0.821 | 0.816 | 0.816 | 0.816 | 0.816 | 16 | 16 |
While minor in this case - and potentially further influenced by the number of features we have chosen and the method by which we have selected them - feature engineering can have a positive impact on your models, and this notebook has hopefully given you an insight into different strategies for creating additional columns in pandas.