5Exercise Solution: Decision Trees (Stroke Thromobolysis Dataset)
The data loaded in this exercise is for seven acute stroke units, and whether a patient receives clost-busting treatment for stroke. There are lots of features, and a description of the features can be found in the file stroke_data_feature_descriptions.csv.
Train a decision tree model to try to predict whether or not a stroke patient receives clot-busting treatment. Use the prompts below to write each section of code.
5.1 Core - Fitting and Evaluating a Decision Tree
Run the code below to import the dataset and the libraries we need.
import pandas as pdimport numpy as np# import preprocessing functionsfrom sklearn.model_selection import train_test_split# Import machine learning model of interestfrom sklearn.tree import DecisionTreeClassifier, plot_tree# Import package to investigate our loaded dataframefrom ydata_profiling import ProfileReport# Import functions for evaluating modelfrom sklearn.metrics import recall_score, precision_score# Imports relating to logistic regressionfrom sklearn.linear_model import LogisticRegressionfrom sklearn.preprocessing import StandardScaler# Imports relating to plottingimport matplotlib.pyplot as plt%matplotlib inlineimport seaborn as sns# Download data# (not required if running locally and have previously downloaded data)download_required =Trueif download_required:# Download processed data: address ='https://raw.githubusercontent.com/MichaelAllen1966/'+\'2004_titanic/master/jupyter_notebooks/data/hsma_stroke.csv' data = pd.read_csv(address)# Create a data subfolder if one does not already existimport os data_directory ='./data/'ifnot os.path.exists(data_directory): os.makedirs(data_directory)# Save data to data subfolder data.to_csv(data_directory +'hsma_stroke.csv', index=False)# Load datadata = pd.read_csv('data/hsma_stroke.csv')# Make all data 'float' typedata = data.astype(float)# Show datadata.head()
Clotbuster given
Hosp_1
Hosp_2
Hosp_3
Hosp_4
Hosp_5
Hosp_6
Hosp_7
Male
Age
...
S2NihssArrivalFacialPalsy
S2NihssArrivalMotorArmLeft
S2NihssArrivalMotorArmRight
S2NihssArrivalMotorLegLeft
S2NihssArrivalMotorLegRight
S2NihssArrivalLimbAtaxia
S2NihssArrivalSensory
S2NihssArrivalBestLanguage
S2NihssArrivalDysarthria
S2NihssArrivalExtinctionInattention
0
1.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
63.0
...
3.0
4.0
0.0
4.0
0.0
0.0
0.0
0.0
1.0
1.0
1
1.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
85.0
...
0.0
0.0
0.0
0.0
0.0
0.0
0.0
2.0
1.0
0.0
2
0.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
91.0
...
0.0
1.0
0.0
0.0
0.0
1.0
0.0
0.0
0.0
0.0
3
0.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
90.0
...
1.0
1.0
0.0
1.0
0.0
0.0
1.0
0.0
1.0
0.0
4
1.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
69.0
...
2.0
0.0
4.0
1.0
4.0
0.0
1.0
2.0
2.0
1.0
5 rows × 51 columns
Look at an overview of the data by running the code below.
We’re going to use a library we haven’t covered before to give a quick summary of the dataframe.
You used this data last week, so it should feel familiar to you.
Do you prefer this method or the code you used last week in the logistic regression exercise?
Load in the ‘stroke_data_feature_descriptions’ dataframe and view that too - you can just view the whole dataframe with pandas rather than using the ProfileReport.
Hint: it’s in the same folder as the hsma_stroke.csv dataset we imported above.
Divide the main stroke dataset into features and labels.
Remember - we’re trying to predict whether patients are given clotbusting treatment or not.
What column contains that information?
X = data.drop('Clotbuster given', axis=1)y = data['Clotbuster given']
Split the data into training and testing sets.
Start with a train/test split of 80/20.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=127)
Fit a Decision Tree model.
model = DecisionTreeClassifier()model.fit(X_train, y_train)
DecisionTreeClassifier()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier()
Use the trained model to predict labels in both training and test sets, and calculate and compare accuracy.
y_pred_train = model.predict(X_train)y_pred_test = model.predict(X_test)accuracy_train = np.mean(y_pred_train == y_train)accuracy_test = np.mean(y_pred_test == y_test)# Note that the lecture slides show this displayed as a float using :3f# We can instead use :.3% to format the number as a percentage to 3 decimal places.print(f"Accuracy of predicting training data = {accuracy_train:.3%}")print(f"Accuracy of predicting testing data = {accuracy_test:.3%}")
Accuracy of predicting training data = 100.000%
Accuracy of predicting testing data = 74.799%
Calculate the additional model metrics for the test data only.
precision
specificity
recall (sensitivity)
Return the ‘micro’ average in each case.
precision_score_test = precision_score(y_test, y_pred_test, average='micro')recall_sensitivity_score_test = recall_score(y_test, y_pred_test, average='micro')specificity_score_test = precision_score(y_test, y_pred_test, pos_label=0)print(f"Precision score for testing data = {precision_score_test:.3%}")print(f"Recall (sensitivity) score for testing data = {recall_sensitivity_score_test:.3%}")print(f"Specificity score for testing data = {specificity_score_test:.3%}")
Precision score for testing data = 74.799%
Recall (sensitivity) score for testing data = 74.799%
Specificity score for testing data = 78.404%
# we learn this in a later session - but a nice way to compare and contrastfrom sklearn.metrics import classification_reportprint(classification_report(y_test, y_pred_test))
Try changing the value of the ‘max_depth’ parameter when setting up your DecisionTreeClassifier.
Output the - accuracy (train and test) - precision (test) - specificity (test) - and recall (sensitivity) (test)
of this new classifier.
We’ve switched to ‘macro’ average from here on in - take a look at the second half of session 4D for more detail on this.
model = DecisionTreeClassifier(max_depth=5)model.fit(X_train, y_train)y_pred_train = model.predict(X_train)y_pred_test = model.predict(X_test)accuracy_train = np.mean(y_pred_train == y_train)accuracy_test = np.mean(y_pred_test == y_test)precision_score_test = precision_score(y_test, y_pred_test, average='macro')recall_sensitivity_score_test = recall_score(y_test, y_pred_test, average='macro')specificity_score_test = precision_score(y_test, y_pred_test, pos_label=0)# Note that the lecture slides show this displayed as a float using :3f# We can instead use :.3% to format the number as a percentage to 3 decimal places.print(f"Accuracy of predicting training data = {accuracy_train:.3%}")print(f"Accuracy of predicting testing data = {accuracy_test:.3%}")print(f"Precision score for testing data = {precision_score_test:.3%}")print(f"Recall (sensitivity) score for testing data = {recall_sensitivity_score_test:.3%}")print(f"Specificity score for testing data = {specificity_score_test:.3%}")
Accuracy of predicting training data = 80.591%
Accuracy of predicting testing data = 80.965%
Precision score for testing data = 80.767%
Recall (sensitivity) score for testing data = 81.475%
Specificity score for testing data = 87.500%
model = DecisionTreeClassifier(max_depth=3)model.fit(X_train, y_train)y_pred_train = model.predict(X_train)y_pred_test = model.predict(X_test)accuracy_train = np.mean(y_pred_train == y_train)accuracy_test = np.mean(y_pred_test == y_test)precision_score_test = precision_score(y_test, y_pred_test, average='macro')recall_sensitivity_score_test = recall_score(y_test, y_pred_test, average='macro')specificity_score_test = precision_score(y_test, y_pred_test, pos_label=0)# Note that the lecture slides show this displayed as a float using :3f# We can instead use :.3% to format the number as a percentage to 3 decimal places.print(f"Accuracy of predicting training data = {accuracy_train:.3%}")print(f"Accuracy of predicting testing data = {accuracy_test:.3%}")print(f"Precision score for testing data = {precision_score_test:.3%}")print(f"Recall (sensitivity) score for testing data = {recall_sensitivity_score_test:.3%}")print(f"Specificity score for testing data = {specificity_score_test:.3%}")
Accuracy of predicting training data = 78.308%
Accuracy of predicting testing data = 77.748%
Precision score for testing data = 77.338%
Recall (sensitivity) score for testing data = 77.845%
Specificity score for testing data = 83.000%
This is getting very tiresome - let’s write a function!
def fit_dt_model(model): model.fit(X_train, y_train) y_pred_train = model.predict(X_train) y_pred_test = model.predict(X_test) accuracy_train = np.mean(y_pred_train == y_train) accuracy_test = np.mean(y_pred_test == y_test) precision_score_test = precision_score(y_test, y_pred_test, average='micro') recall_sensitivity_score_test = recall_score(y_test, y_pred_test, average='micro') specificity_score_test = precision_score(y_test, y_pred_test, pos_label=0)# Note that the lecture slides show this displayed as a float using :3f# We can instead use :.3% to format the number as a percentage to 3 decimal places.print(f"Accuracy of predicting training data = {accuracy_train:.3%}")print(f"Accuracy of predicting testing data = {accuracy_test:.3%}")print(f"Precision score for testing data = {precision_score_test:.3%}")print(f"Recall (sensitivity) score for testing data = {recall_sensitivity_score_test:.3%}")print(f"Specificity score for testing data = {specificity_score_test:.3%}")fit_dt_model(model = DecisionTreeClassifier(max_depth=8, random_state=42))
Accuracy of predicting training data = 86.367%
Accuracy of predicting testing data = 78.820%
Precision score for testing data = 78.820%
Recall (sensitivity) score for testing data = 78.820%
Specificity score for testing data = 83.010%
Accuracy of predicting training data = 79.449%
Accuracy of predicting testing data = 80.161%
Precision score for testing data = 80.161%
Recall (sensitivity) score for testing data = 80.161%
Specificity score for testing data = 80.786%
5.2.2 Minimum Samples
Try changing the values of ‘min_samples_split’ (the default value is 2).
Accuracy of predicting training data = 95.097%
Accuracy of predicting testing data = 74.531%
Precision score for testing data = 74.531%
Recall (sensitivity) score for testing data = 74.531%
Specificity score for testing data = 76.549%
Accuracy of predicting training data = 97.381%
Accuracy of predicting testing data = 76.408%
Precision score for testing data = 76.408%
Recall (sensitivity) score for testing data = 76.408%
Specificity score for testing data = 79.535%
Now try adjusting ‘min_samples_leaf’ (the default is 1).
Accuracy of predicting training data = 87.710%
Accuracy of predicting testing data = 77.748%
Precision score for testing data = 77.748%
Recall (sensitivity) score for testing data = 77.748%
Specificity score for testing data = 77.049%
Accuracy of predicting training data = 99.127%
Accuracy of predicting testing data = 73.727%
Precision score for testing data = 73.727%
Recall (sensitivity) score for testing data = 73.727%
Specificity score for testing data = 76.233%
**Gini**
Accuracy of predicting training data = 100.000%
Accuracy of predicting testing data = 75.335%
Precision score for testing data = 75.335%
Recall (sensitivity) score for testing data = 75.335%
Specificity score for testing data = 78.605%
**Entropy**
Accuracy of predicting training data = 100.000%
Accuracy of predicting testing data = 77.212%
Precision score for testing data = 77.212%
Recall (sensitivity) score for testing data = 77.212%
Specificity score for testing data = 79.545%
**Log Loss**
Accuracy of predicting training data = 100.000%
Accuracy of predicting testing data = 77.212%
Precision score for testing data = 77.212%
Recall (sensitivity) score for testing data = 77.212%
Specificity score for testing data = 79.545%
5.3 Comparing Performance with a Logistic Regression Model
Copy your code in from last week’s logistic regression exercise (or write this in from scratch - there isn’t much that is different to the decision tree model!).
Remember - you will need to standardise the data for the logistic regression model!
Look at these additional metrics as well:
precision
specificity
recall (sensitivity)
scaler = StandardScaler()X_train_stand = scaler.fit_transform(X_train)X_test_stand = scaler.fit_transform(X_test)model = LogisticRegression()model.fit(X_train_stand, y_train)y_pred_train = model.predict(X_train_stand)y_pred_test = model.predict(X_test_stand)accuracy_train = np.mean(y_pred_train == y_train)accuracy_test = np.mean(y_pred_test == y_test)precision_score_test = precision_score(y_test, y_pred_test, average='micro')recall_sensitivity_score_test = recall_score(y_test, y_pred_test, average='micro')specificity_score_test = precision_score(y_test, y_pred_test, pos_label=0)# Note that the lecture slides show this displayed as a float using :3f# We can instead use :.3% to format the number as a percentage to 3 decimal places.print(f"Accuracy of predicting training data = {accuracy_train:.3%}")print(f"Accuracy of predicting testing data = {accuracy_test:.3%}")print(f"Precision score for testing data = {precision_score_test:.3%}")print(f"Recall (sensitivity) score for testing data = {recall_sensitivity_score_test:.3%}")print(f"Specificity score for testing data = {specificity_score_test:.3%}")
Accuracy of predicting training data = 81.531%
Accuracy of predicting testing data = 82.574%
Precision score for testing data = 82.574%
Recall (sensitivity) score for testing data = 82.574%
Specificity score for testing data = 83.784%
Use the cell below to write out an interpretation of the performance of the logistic regression model and the decision tree.
Think about the presence of false positives and false negatives.
Which might you be more interested in minimizing in this model?
Hint - giving thrombolysis to good candidates for it can lead to less disability after stroke and improved outcomes. However, there is a risk that giving thrombolysis to the wrong person could lead to additional bleeding on the brain and worse outcomes. What might you want to balance?
No answer given
5.4 Challenge Exercises
5.4.1 Bonus Exercise 1
Have a read of this article on feature importance in decision trees: Article Link
In particular, make sure you read the section “Pros and cons of using Gini importance” so you can understand some of the things you need to keep in mind when looking at feature importance in trees.
We can access the feature importance by running the following code:
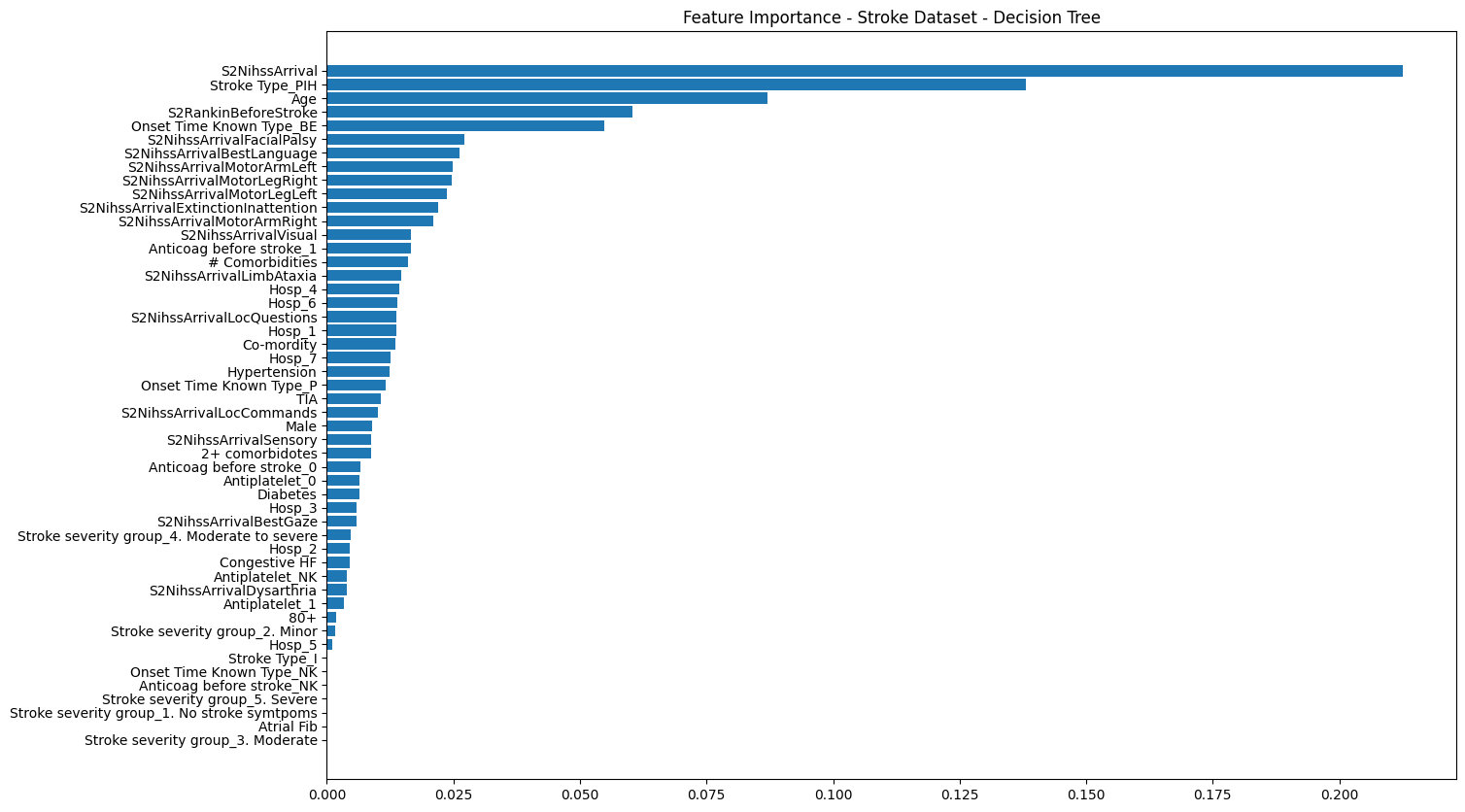
# modify this code to point towards your decision tree model object (make sure that object# was using the gini index as the criteria)model_dt = DecisionTreeClassifier(criterion="gini", random_state=42)model_dt = model_dt.fit(X_train, y_train)feature_importances_dt = model_dt.feature_importances_feature_importances_dt
How does this compare to the feature importance for your logistic regression?
HINT: This is quite different from the approach used in the model.
You’ll need to look back at the exercises form last week.
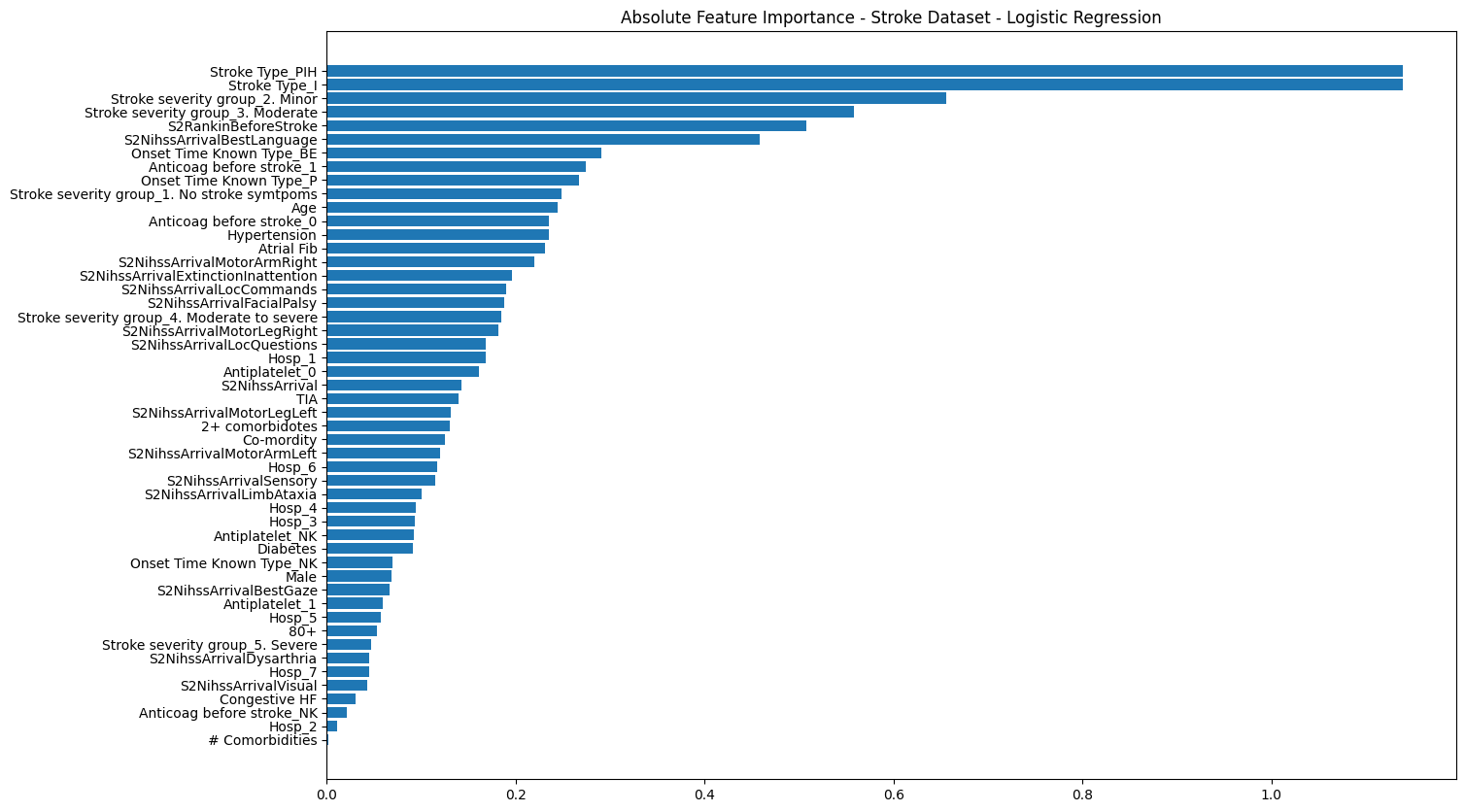
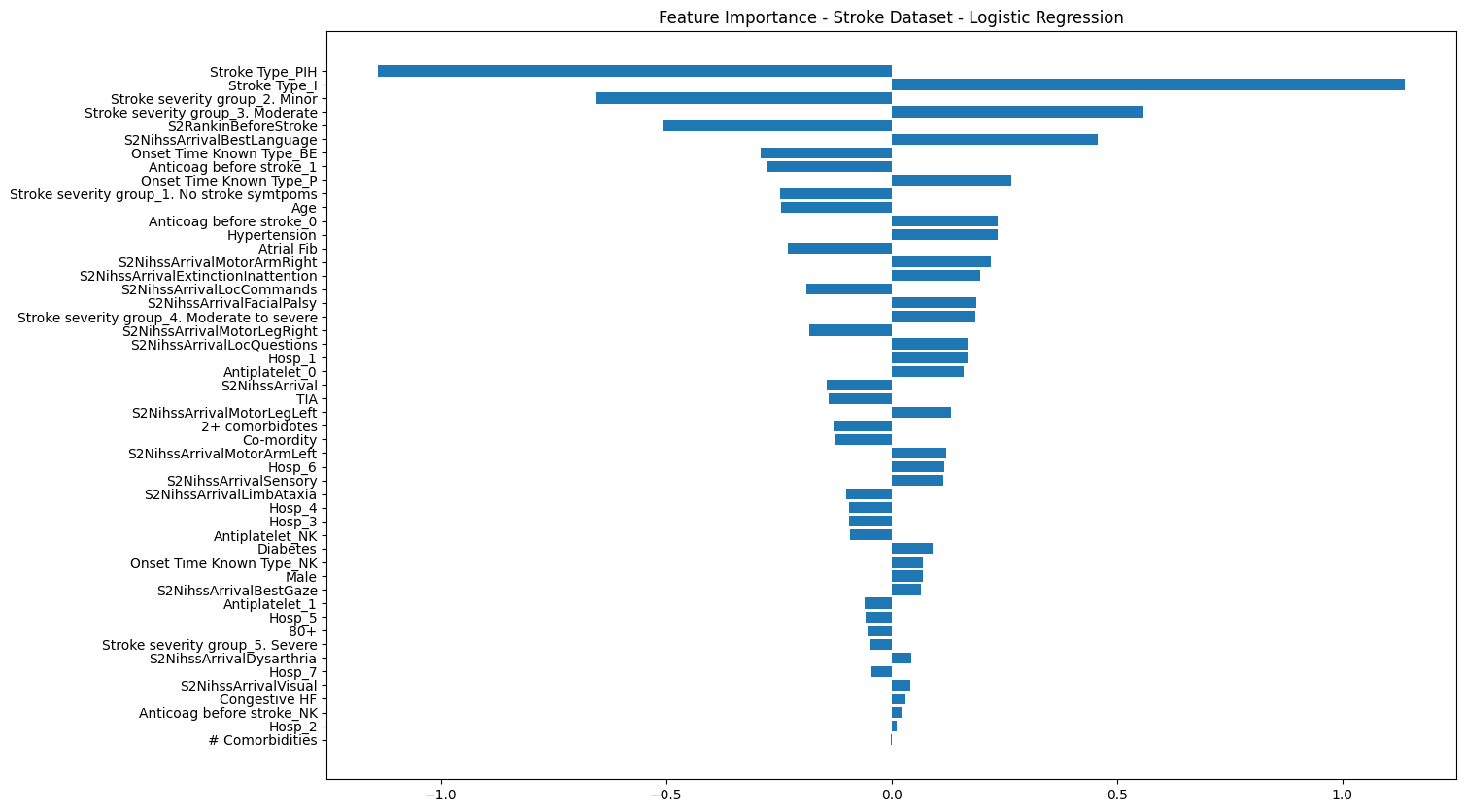
# modify this code to point towards your logistic regression model objectscaler = StandardScaler()X_train_stand = scaler.fit_transform(X_train)X_test_stand = scaler.fit_transform(X_test)model_lr = LogisticRegression()model_lr = model_lr.fit(X_train_stand, y_train)# Examine feature weights and sort by most influentialco_eff = model_lr.coef_[0]co_eff_df = pd.DataFrame()co_eff_df['feature'] =list(X)co_eff_df['co_eff'] = co_effco_eff_df['abs_co_eff'] = np.abs(co_eff)co_eff_df.sort_values(by='abs_co_eff', ascending=False, inplace=True)co_eff_df
feature
co_eff
abs_co_eff
33
Stroke Type_PIH
-1.138691
1.138691
32
Stroke Type_I
1.138691
1.138691
28
Stroke severity group_2. Minor
-0.655217
0.655217
29
Stroke severity group_3. Moderate
0.558470
0.558470
34
S2RankinBeforeStroke
-0.507321
0.507321
47
S2NihssArrivalBestLanguage
0.458131
0.458131
10
Onset Time Known Type_BE
-0.290595
0.290595
25
Anticoag before stroke_1
-0.274249
0.274249
12
Onset Time Known Type_P
0.266564
0.266564
27
Stroke severity group_1. No stroke symtpoms
-0.248087
0.248087
8
Age
-0.244158
0.244158
24
Anticoag before stroke_0
0.235502
0.235502
16
Hypertension
0.235309
0.235309
17
Atrial Fib
-0.230893
0.230893
42
S2NihssArrivalMotorArmRight
0.219366
0.219366
49
S2NihssArrivalExtinctionInattention
0.195696
0.195696
37
S2NihssArrivalLocCommands
-0.189860
0.189860
40
S2NihssArrivalFacialPalsy
0.187638
0.187638
30
Stroke severity group_4. Moderate to severe
0.185069
0.185069
44
S2NihssArrivalMotorLegRight
-0.181887
0.181887
36
S2NihssArrivalLocQuestions
0.168651
0.168651
0
Hosp_1
0.168301
0.168301
21
Antiplatelet_0
0.161005
0.161005
35
S2NihssArrival
-0.142778
0.142778
19
TIA
-0.138909
0.138909
43
S2NihssArrivalMotorLegLeft
0.131229
0.131229
14
2+ comorbidotes
-0.129622
0.129622
20
Co-mordity
-0.124540
0.124540
41
S2NihssArrivalMotorArmLeft
0.120298
0.120298
5
Hosp_6
0.116469
0.116469
46
S2NihssArrivalSensory
0.114362
0.114362
45
S2NihssArrivalLimbAtaxia
-0.099983
0.099983
3
Hosp_4
-0.093776
0.093776
2
Hosp_3
-0.093303
0.093303
23
Antiplatelet_NK
-0.092551
0.092551
18
Diabetes
0.090665
0.090665
11
Onset Time Known Type_NK
0.069936
0.069936
7
Male
0.068703
0.068703
38
S2NihssArrivalBestGaze
0.065874
0.065874
22
Antiplatelet_1
-0.059578
0.059578
4
Hosp_5
-0.057283
0.057283
9
80+
-0.053481
0.053481
31
Stroke severity group_5. Severe
-0.047326
0.047326
48
S2NihssArrivalDysarthria
0.044316
0.044316
6
Hosp_7
-0.044271
0.044271
39
S2NihssArrivalVisual
0.042245
0.042245
15
Congestive HF
0.030292
0.030292
26
Anticoag before stroke_NK
0.021401
0.021401
1
Hosp_2
0.010540
0.010540
13
# Comorbidities
-0.001275
0.001275
Can you create two graphs showing feature importance for the two models?
Instead of using the plot code used in the linked article, try looking up the barh function from matplotlib.
Try ordering your plot so that the features with the most importance are at the top.
# Sort the feature importances from greatest to least using the sorted indicessorted_indices = feature_importances_dt.argsort()[::-1]sorted_feature_names =[X.columns[i] for i in sorted_indices]sorted_importances = feature_importances_dt[sorted_indices]# Create a bar plot of the feature importancesfig, ax = plt.subplots(figsize=(15,10))ax.barh(width=sorted_importances, y=sorted_feature_names)ax.invert_yaxis()ax = plt.title("Feature Importance - Stroke Dataset - Decision Tree")
Accuracy of predicting training data = 100.000%
Accuracy of predicting testing data = 74.866%
Precision score for testing data = 74.866%
Recall (sensitivity) score for testing data = 74.866%
Specificity score for testing data = 81.250%
Accuracy of predicting training data = 100.000%
Accuracy of predicting testing data = 76.923%
Precision score for testing data = 76.923%
Recall (sensitivity) score for testing data = 76.923%
Specificity score for testing data = 80.588%
5.4.3 Bonus Exercise 3
Try dropping some features from your data.
Can you improve the performance of your model this way?
NOTE: This solution just shows selecting a subset of features - not the best ones necessarily!
X.columns
Index(['Hosp_1', 'Hosp_2', 'Hosp_3', 'Hosp_4', 'Hosp_5', 'Hosp_6', 'Hosp_7',
'Male', 'Age', '80+', 'Onset Time Known Type_BE',
'Onset Time Known Type_NK', 'Onset Time Known Type_P',
'# Comorbidities', '2+ comorbidotes', 'Congestive HF', 'Hypertension',
'Atrial Fib', 'Diabetes', 'TIA', 'Co-mordity', 'Antiplatelet_0',
'Antiplatelet_1', 'Antiplatelet_NK', 'Anticoag before stroke_0',
'Anticoag before stroke_1', 'Anticoag before stroke_NK',
'Stroke severity group_1. No stroke symtpoms',
'Stroke severity group_2. Minor', 'Stroke severity group_3. Moderate',
'Stroke severity group_4. Moderate to severe',
'Stroke severity group_5. Severe', 'Stroke Type_I', 'Stroke Type_PIH',
'S2RankinBeforeStroke', 'S2NihssArrival', 'S2NihssArrivalLocQuestions',
'S2NihssArrivalLocCommands', 'S2NihssArrivalBestGaze',
'S2NihssArrivalVisual', 'S2NihssArrivalFacialPalsy',
'S2NihssArrivalMotorArmLeft', 'S2NihssArrivalMotorArmRight',
'S2NihssArrivalMotorLegLeft', 'S2NihssArrivalMotorLegRight',
'S2NihssArrivalLimbAtaxia', 'S2NihssArrivalSensory',
'S2NihssArrivalBestLanguage', 'S2NihssArrivalDysarthria',
'S2NihssArrivalExtinctionInattention'],
dtype='object')
Accuracy of predicting training data = 80.583%
Accuracy of predicting testing data = 80.680%
Precision score for testing data = 80.680%
Recall (sensitivity) score for testing data = 80.680%
Specificity score for testing data = 89.895%
# This isn't necessarily the best subset of features to use - it's just an example!X_reduced = X[['S2NihssArrival', 'Stroke Type_PIH', 'Age', 'S2RankinBeforeStroke']]X_reduced_train, X_reduced_test, y_train, y_test = train_test_split(X_reduced, y, test_size=0.1, random_state=42)model = DecisionTreeClassifier(max_depth=5, random_state=42)model.fit(X_reduced_train, y_train)y_pred_train = model.predict(X_reduced_train)y_pred_test = model.predict(X_reduced_test)accuracy_train = np.mean(y_pred_train == y_train)accuracy_test = np.mean(y_pred_test == y_test)precision_score_test = precision_score(y_test, y_pred_test, average='micro')recall_sensitivity_score_test = recall_score(y_test, y_pred_test, average='micro')specificity_score_test = precision_score(y_test, y_pred_test, pos_label=0)# Note that the lecture slides show this displayed as a float using :3f# We can instead use :.3% to format the number as a percentage to 3 decimal places.print(f"Accuracy of predicting training data = {accuracy_train:.3%}")print(f"Accuracy of predicting testing data = {accuracy_test:.3%}")print(f"Precision score for testing data = {precision_score_test:.3%}")print(f"Recall (sensitivity) score for testing data = {recall_sensitivity_score_test:.3%}")print(f"Specificity score for testing data = {specificity_score_test:.3%}")
Accuracy of predicting training data = 79.821%
Accuracy of predicting testing data = 77.540%
Precision score for testing data = 77.540%
Recall (sensitivity) score for testing data = 77.540%
Specificity score for testing data = 86.408%