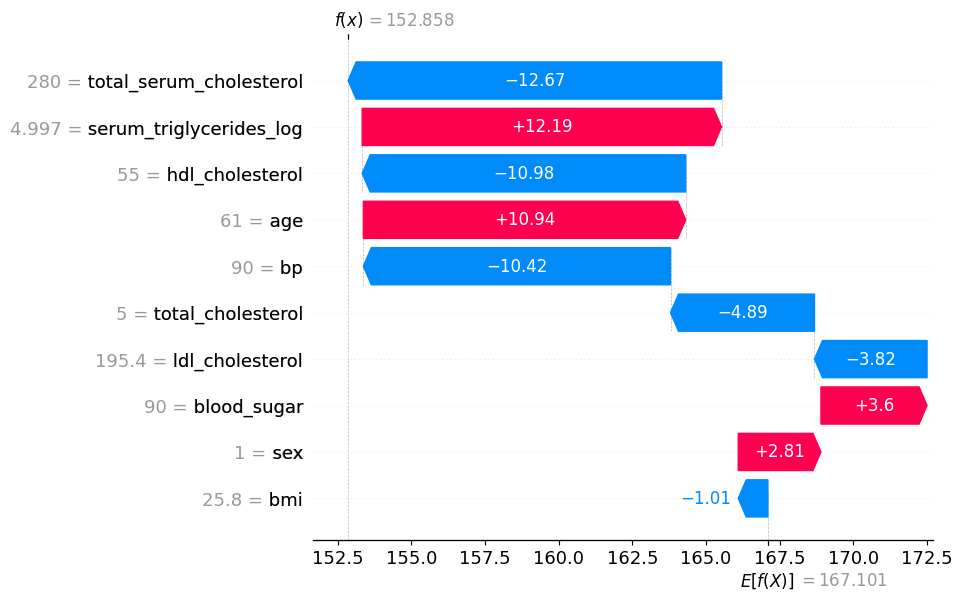
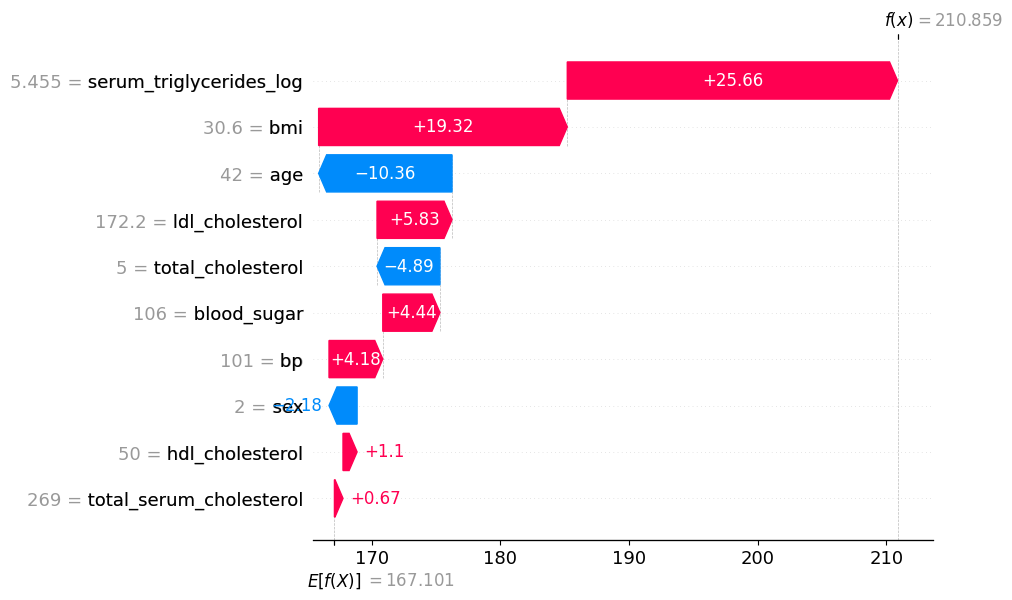
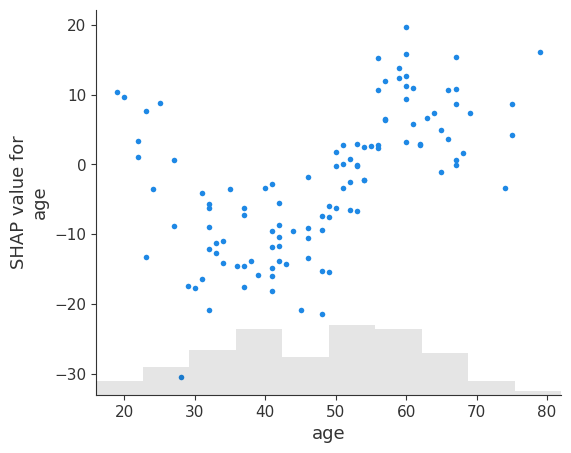
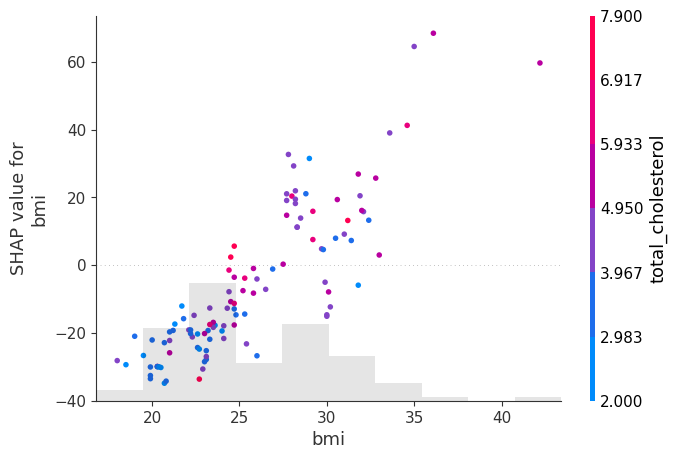
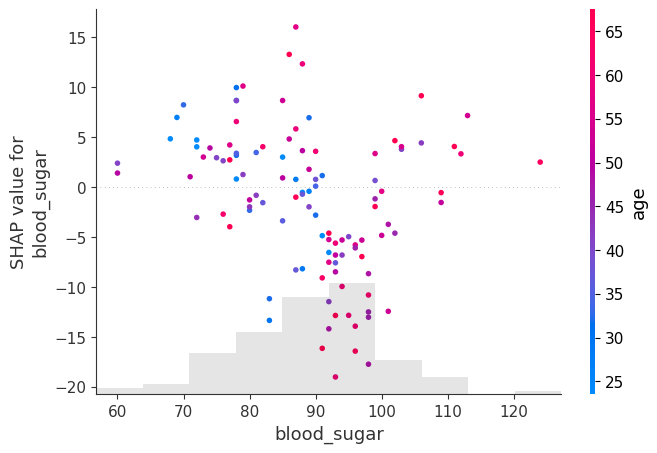
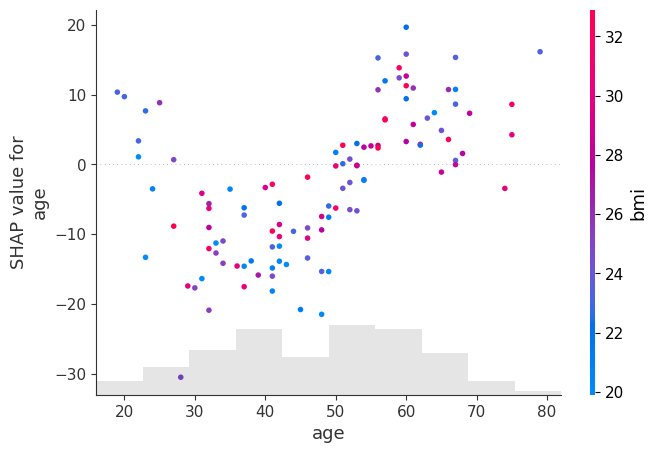
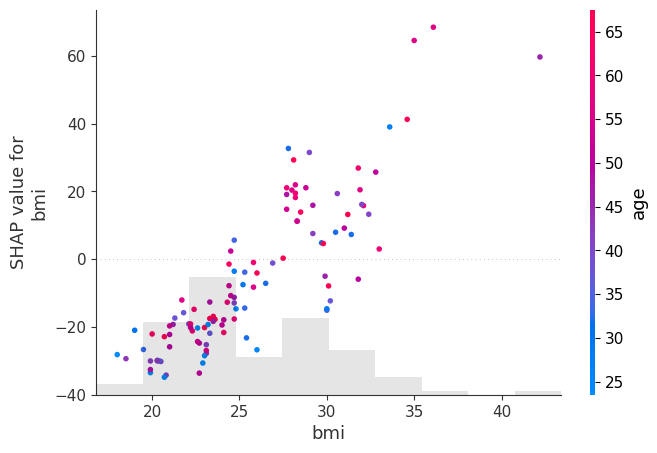
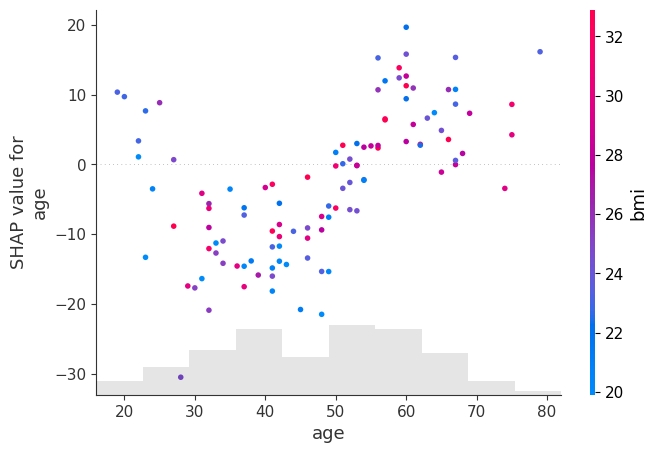
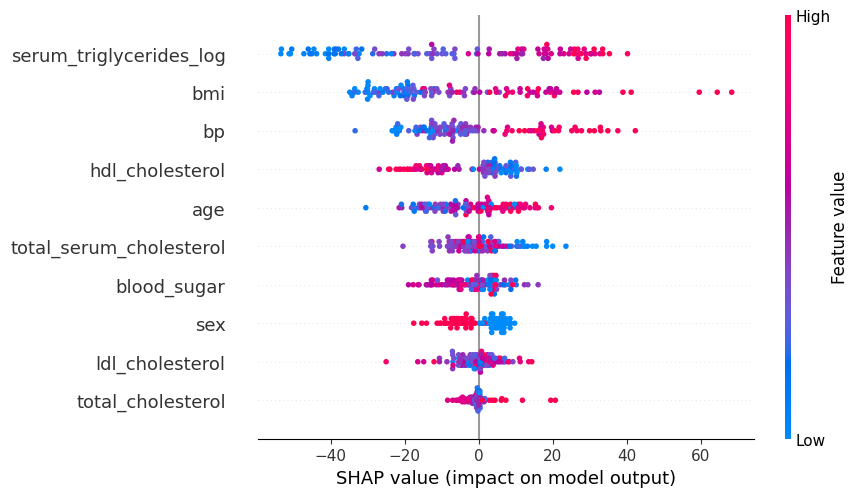
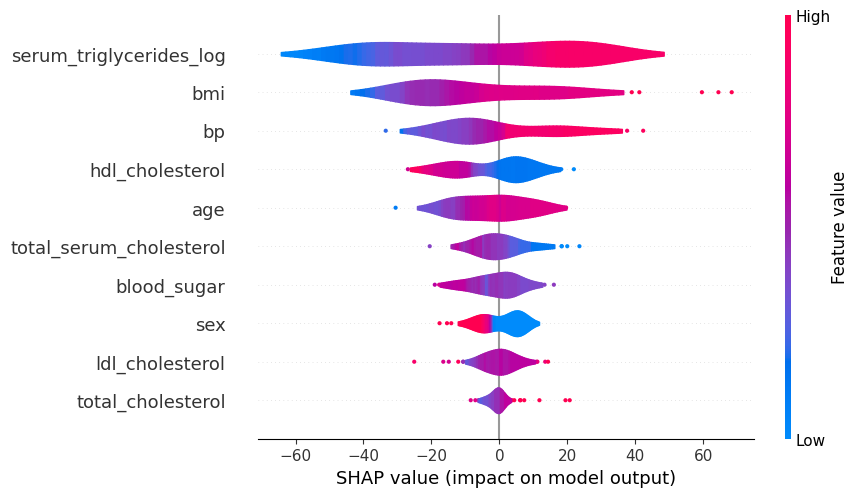
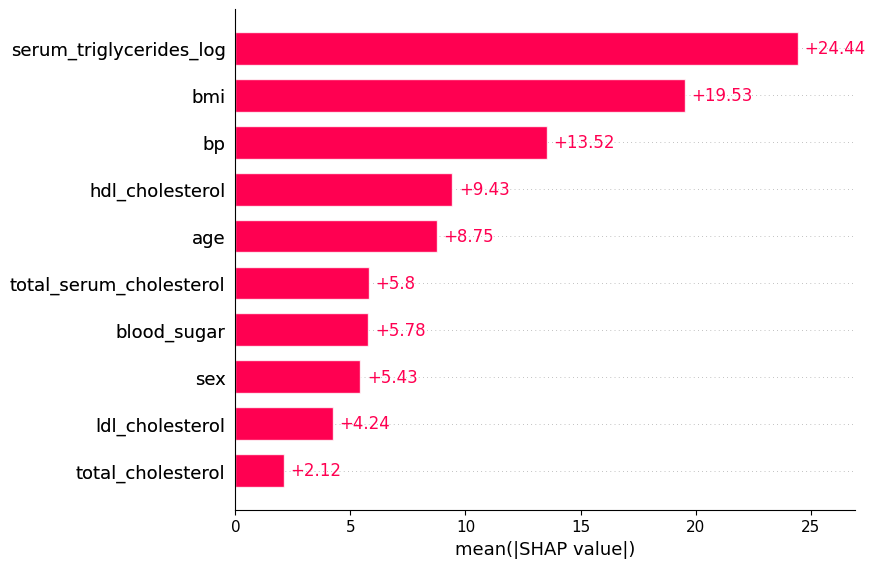
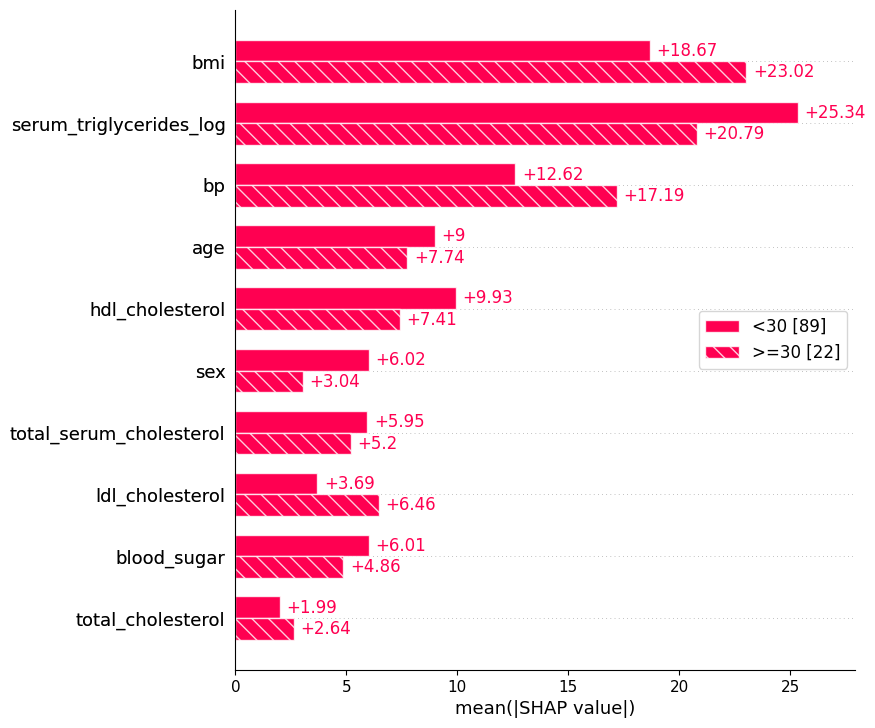
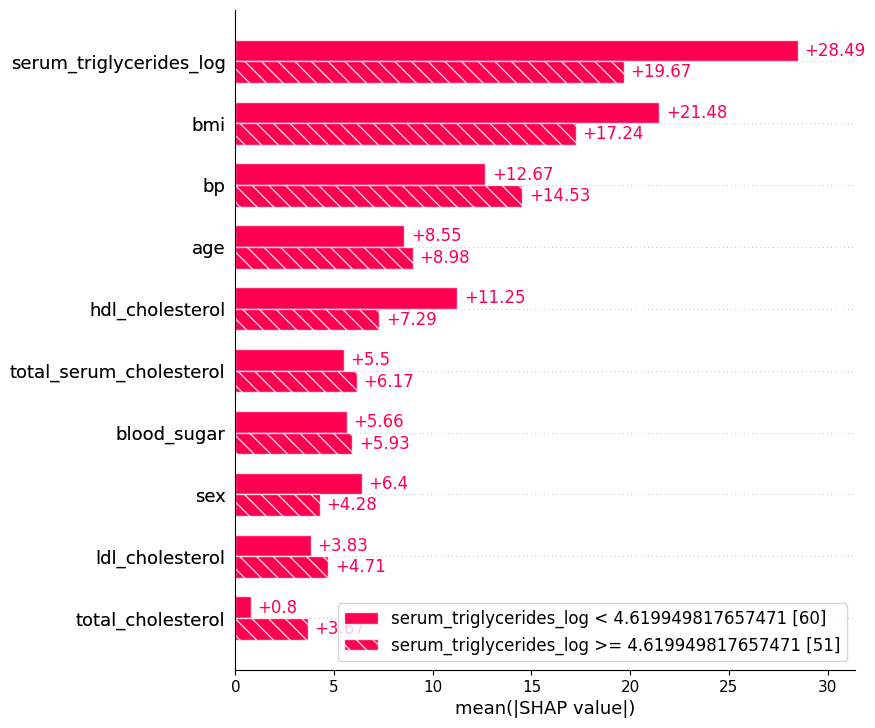
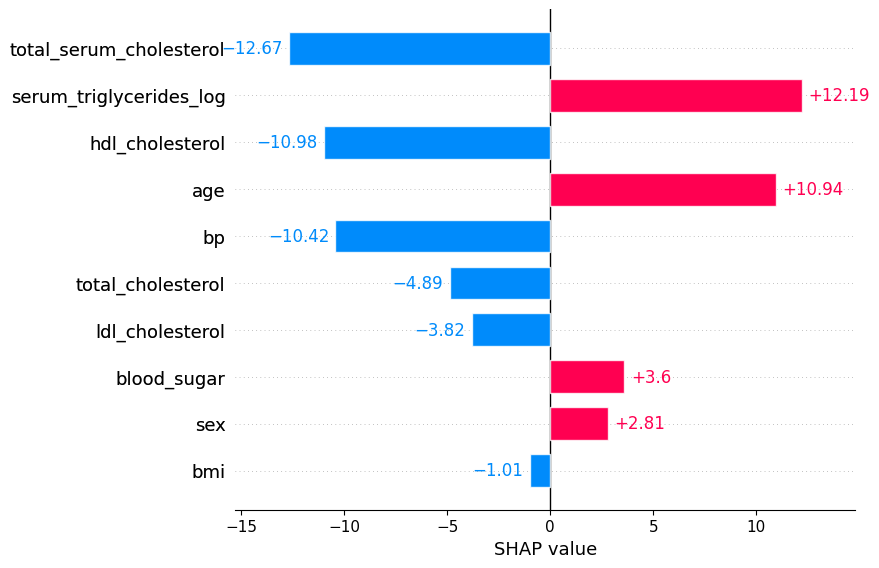
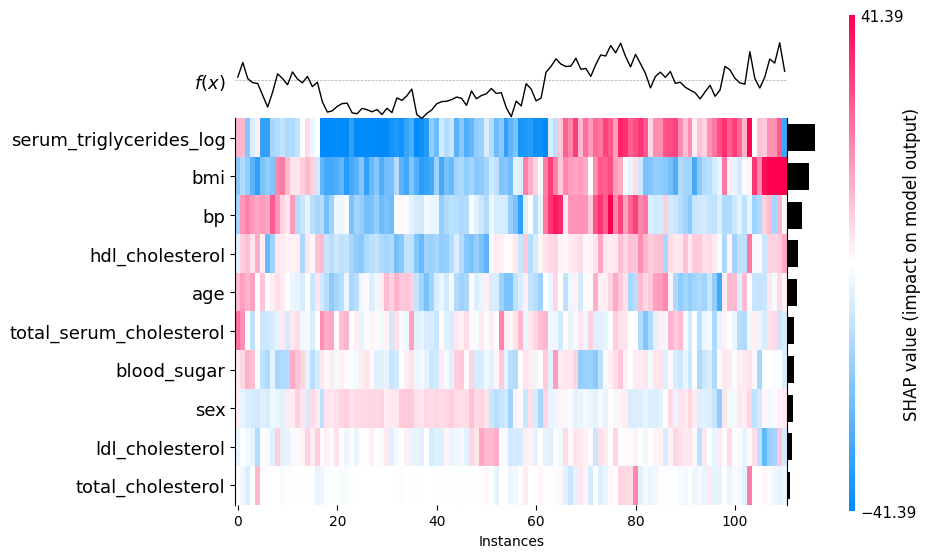
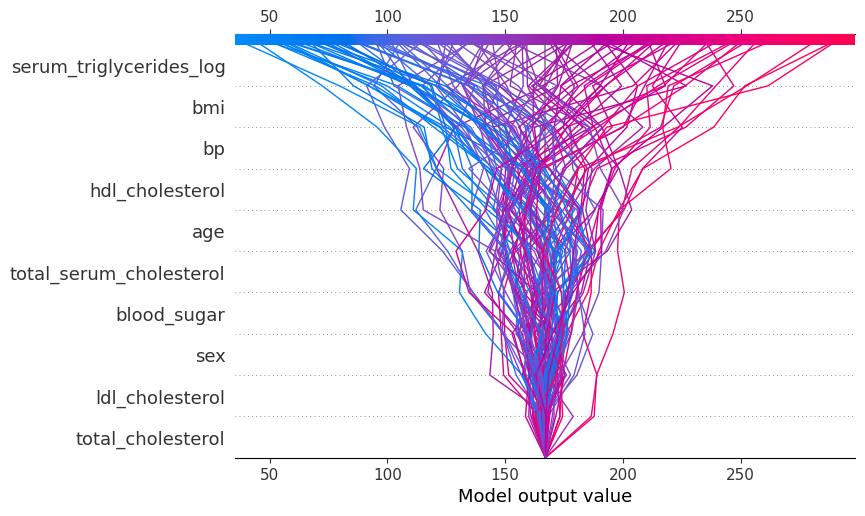
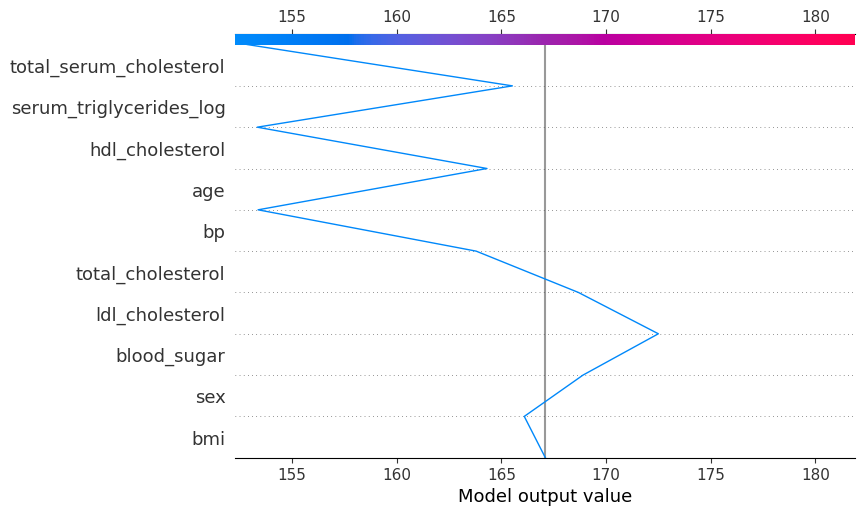
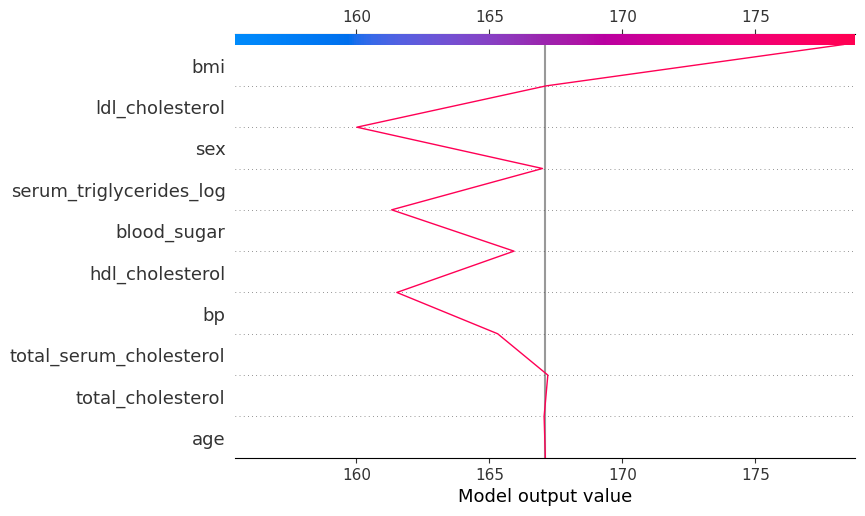
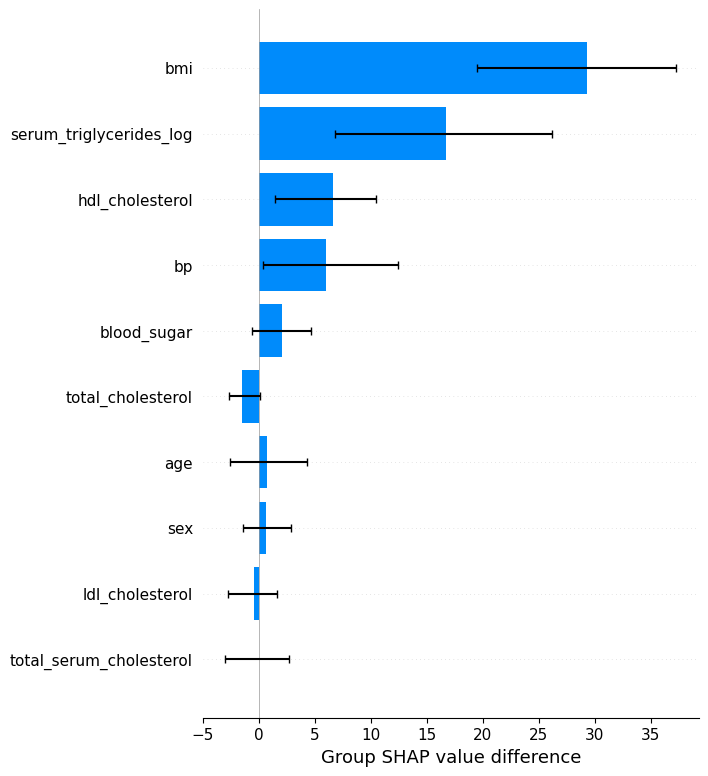
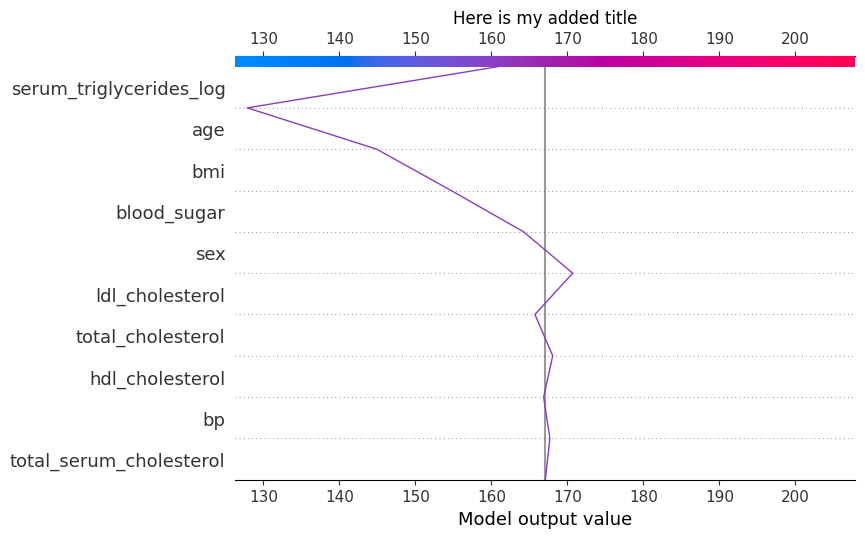
.values =
array([[ 10.93827235, 2.8060772 , -1.00666967, ..., -4.88568904,
12.19191076, 3.60045137],
[ -3.45617191, 3.4392566 , 4.56441772, ..., 0.37978809,
-13.22084821, 13.30567497],
[ 10.71647202, -1.89627643, -4.11494224, ..., -1.75186097,
31.18730879, -0.99276986],
...,
[ 2.63871242, 4.10990574, 21.90833779, ..., 0.12410758,
33.50004507, 4.06646104],
[ -0.19391851, 7.1562762 , 21.04501401, ..., 0.28448169,
-46.11341172, 8.68782261],
[ 8.6260937 , -5.57821297, -20.22131193, ..., -3.46062915,
6.32432399, -1.93388196]])
.base_values =
array([167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748, 167.10061748,
167.10061748, 167.10061748, 167.10061748])
.data =
array([[ 61. , 1. , 25.8 , ..., 5. , 4.9972, 90. ],
[ 74. , 1. , 29.8 , ..., 3. , 4.3944, 86. ],
[ 66. , 2. , 26. , ..., 4. , 5.5683, 87. ],
...,
[ 55. , 1. , 28.2 , ..., 4. , 5.366 , 103. ],
[ 53. , 1. , 28.8 , ..., 3.15 , 4.0775, 85. ],
[ 67. , 2. , 23. , ..., 5. , 4.654 , 99. ]])