try:
from flaml import AutoML
except ModuleNotFoundError:
!pip install flaml
import pandas as pd
import numpy as np
# Machine learning setup imports
from sklearn.model_selection import train_test_split
# Model imports
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from catboost import CatBoostClassifier
# Model scoring imports
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix, f1_score, precision_score, \
recall_score, roc_auc_score23 Automated Machine Learning (Titanic Dataset)
The flaml library from Microsoft can automate the process of selecting a model and appropriate hyperparameters.
It is just one of the automated machine learning libraries out there!
First, let’s import the flaml library, along with our standard imports for data manipulation and machine learning.
We’re going to work with the preprocessed titanic data, splitting it into training, validation and testing datasets.
try:
data = pd.read_csv("data/processed_data.csv")
except FileNotFoundError:
# Download processed data:
address = 'https://raw.githubusercontent.com/MichaelAllen1966/' + \
'1804_python_healthcare/master/titanic/data/processed_data.csv'
data = pd.read_csv(address)
# Create a data subfolder if one does not already exist
import os
data_directory ='./data/'
if not os.path.exists(data_directory):
os.makedirs(data_directory)
# Save data
data.to_csv(data_directory + 'processed_data.csv', index=False)
data = data.astype(float)
# Drop Passengerid (axis=1 indicates we are removing a column rather than a row)
# We drop passenger ID as it is not original data
data.drop('PassengerId', inplace=True, axis=1)
X = data.drop('Survived',axis=1) # X = all 'data' except the 'survived' column
y = data['Survived'] # y = 'survived' column from 'data'
feature_names = X.columns.tolist()
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_validate, y_train, y_validate = train_test_split(X_train_val, y_train_val, test_size=0.2, random_state=42)
print(f"Training Dataset Samples: {len(X_train)}")
print(f"Validation Dataset Samples: {len(X_validate)}")
print(f"Testing Dataset Samples: {len(X_test)}")Training Dataset Samples: 569
Validation Dataset Samples: 143
Testing Dataset Samples: 17923.1 Simple initial auto ML training
Let’s try out a simple instance of automated training with flaml.
We need to pass in training and testing data, tell it what kind of task we’re conducting (e.g. classification, regression), how long to keep trying different models (here, we’ve gone for 60 seconds), and set a random seed for reproducibility.
automl = AutoML()
automl.fit(X_train, y_train,
task="classification",
time_budget=60,
seed=42)We can run this line to see what model it selected.
automl.model<flaml.automl.model.CatBoostEstimator at 0x28d4942f150>And this will give us the parameters it chose.
automl.best_config{'early_stopping_rounds': 10,
'learning_rate': 0.08181308076296119,
'n_estimators': 21}Finally, we can output the best configuration for each of the estimators it tried.
automl.best_config_per_estimator{'lgbm': {'n_estimators': 5,
'num_leaves': 35,
'min_child_samples': 12,
'learning_rate': 0.6152167721646307,
'log_max_bin': 9,
'colsample_bytree': 0.9236754665076755,
'reg_alpha': 0.0009765625,
'reg_lambda': 2.5956586580400387},
'rf': {'n_estimators': 8,
'max_features': 0.3522661192428198,
'max_leaves': 11,
'criterion': 'gini'},
'catboost': {'early_stopping_rounds': 10,
'learning_rate': 0.08181308076296119,
'n_estimators': 21},
'xgboost': {'n_estimators': 49,
'max_leaves': 8,
'min_child_weight': 1.6432463021924941,
'learning_rate': 0.1014993900453572,
'subsample': 0.892732835389516,
'colsample_bylevel': 1.0,
'colsample_bytree': 1.0,
'reg_alpha': 0.26675517308462793,
'reg_lambda': 0.023187687303412453},
'extra_tree': {'n_estimators': 9,
'max_features': 0.21337293465256343,
'max_leaves': 14,
'criterion': 'gini'},
'xgb_limitdepth': {'n_estimators': 9,
'max_depth': 7,
'min_child_weight': 1.5981523613778321,
'learning_rate': 0.4433369998455015,
'subsample': 0.9186551030103914,
'colsample_bylevel': 1.0,
'colsample_bytree': 0.9480491857726955,
'reg_alpha': 0.0009765625,
'reg_lambda': 0.15817424342486922},
'lrl1': None}Now let’s evaluate this model and put the results into a dataframe.
We can use our automl variable where we’d usually use model.
y_pred_train = automl.predict(X_train)
y_pred_val = automl.predict(X_validate)
tn, fp, fn, tp = confusion_matrix(y_validate, y_pred_val, labels=[0, 1]).ravel()
results_df = pd.DataFrame({
'Accuracy (training)': np.mean(y_pred_train == y_train),
'Accuracy (validation)': np.mean(y_pred_val == y_validate),
'Precision (validation)': precision_score(y_validate, y_pred_val, average='macro'),
'Recall (validation)': recall_score(y_validate, y_pred_val, average='macro'),
"AUC": roc_auc_score(y_validate, y_pred_val),
"Training AUC": roc_auc_score(y_train, y_pred_train),
"f1": f1_score(y_validate, y_pred_val, average='macro'),
"Training f1": f1_score(y_train, y_pred_train, average='macro'),
"FP": fp,
"FN": fn
}, index=["Auto ML - Default Parameters - Scoring on ROC AUC"]
).round(3)
results_df| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | Training AUC | f1 | Training f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|---|---|
| Auto ML - Default Parameters - Scoring on ROC AUC | 0.863 | 0.811 | 0.802 | 0.8 | 0.8 | 0.846 | 0.801 | 0.851 | 13 | 14 |
This seems like pretty reasonable performance, based on our previous interactions with the titanic dataset, though not as good as we’ve seen sometimes.
23.2 Customisation
Let’s define a function that will allow us to quickly calculate and store metrics when assessing the automl library.
def auto_ml_get_results(name):
y_pred_train = automl.predict(X_train)
y_pred_val = automl.predict(X_validate)
tn, fp, fn, tp = confusion_matrix(y_validate, y_pred_val, labels=[0, 1]).ravel()
return pd.DataFrame({
'Accuracy (training)': np.mean(y_pred_train == y_train),
'Accuracy (validation)': np.mean(y_pred_val == y_validate),
'Precision (validation)': precision_score(y_validate, y_pred_val, average='macro'),
'Recall (validation)': recall_score(y_validate, y_pred_val, average='macro'),
"AUC": roc_auc_score(y_validate, y_pred_val),
"Training AUC": roc_auc_score(y_train, y_pred_train),
"f1": f1_score(y_validate, y_pred_val, average='macro'),
"Training f1": f1_score(y_train, y_pred_train, average='macro'),
"FP": fp,
"FN": fn
}, index=[name]
).round(3)Now let’s try training again, this time asking it to score on a different metric - the f1 score.
automl = AutoML()
automl.fit(X_train, y_train,
task="classification",
time_budget=60,
metric="f1",
seed=42)
results_df = pd.concat(
[results_df,
auto_ml_get_results(name="Auto ML - Scoring on f1")]
)23.3 Extending the time
When we ran it with the default settings previously (our first run), the fifth line of the output gave us the estimated time required to find an optimal model.
[flaml.automl.logger: 07-29 12:25:03] {2345} INFO - Estimated sufficient time budget=658s. Estimated necessary time budget=16s.
Let’s allocate this length of time.
automl = AutoML()
automl.fit(X_train, y_train,
task="classification",
time_budget=658,
seed=42)
results_df = pd.concat(
[results_df,
auto_ml_get_results(name="Auto ML - scoring on ROC AUC - Training for ~11 minutes")]
)Let’s view our updated results table.
results_df| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | Training AUC | f1 | Training f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|---|---|
| Auto ML - Default Parameters - Scoring on ROC AUC | 0.863 | 0.811 | 0.802 | 0.800 | 0.800 | 0.846 | 0.801 | 0.851 | 13 | 14 |
| Auto ML - Scoring on f1 | 0.914 | 0.825 | 0.820 | 0.809 | 0.809 | 0.897 | 0.813 | 0.906 | 10 | 15 |
| Auto ML - scoring on ROC AUC - Training for ~11 minutes | 0.884 | 0.797 | 0.787 | 0.792 | 0.792 | 0.863 | 0.789 | 0.872 | 16 | 13 |
23.4 Compare this with some other ML models
Let’s define a function to fit and train any provided model, then return the required metrics to be added onto our table from above.
This will allow us to compare the performance of flaml with specifying the model ourselves.
def fit_train(name="XGBoost", X_train=X_train, X_validate=X_validate,
y_train=y_train, y_validate=y_validate,
model=XGBClassifier(random_state=42)
):
model.fit(X_train, y_train)
y_pred_train = model.predict(X_train)
y_pred_val = model.predict(X_validate)
tn, fp, fn, tp = confusion_matrix(y_validate, y_pred_val, labels=[0, 1]).ravel()
return pd.DataFrame({
'Accuracy (training)': np.mean(y_pred_train == y_train),
'Accuracy (validation)': np.mean(y_pred_val == y_validate),
'Precision (validation)': precision_score(y_validate, y_pred_val, average='macro'),
'Recall (validation)': recall_score(y_validate, y_pred_val, average='macro'),
"AUC": roc_auc_score(y_validate, y_pred_val),
"Training AUC": roc_auc_score(y_train, y_pred_train),
"f1": f1_score(y_validate, y_pred_val, average='macro'),
"Training f1": f1_score(y_train, y_pred_train, average='macro'),
"FP": fp,
"FN": fn
}, index=[name]
).round(3)Let’s use this to quickly assess the performance of a range of other models.
results_df = pd.concat(
[results_df,
fit_train(), # This uses the default - xgboost
fit_train(name="Decision Tree (Defaults)", model=DecisionTreeClassifier()),
fit_train(name="Random Forest (Defaults)", model=RandomForestClassifier(random_state=42)),
fit_train(name="LightGBM (Defaults)", model=LGBMClassifier(random_state=42)),
fit_train(name="Catboost (Defaults)", model=CatBoostClassifier(random_state=42, verbose=False)),
]
)
results_dfLet’s sort this by validation accuracy.
results_df.sort_values("Accuracy (validation)", ascending=False)| Accuracy (training) | Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | Training AUC | f1 | Training f1 | FP | FN | |
|---|---|---|---|---|---|---|---|---|---|---|
| Auto ML - Scoring on f1 | 0.914 | 0.825 | 0.820 | 0.809 | 0.809 | 0.897 | 0.813 | 0.906 | 10 | 15 |
| LightGBM (Defaults) | 0.961 | 0.818 | 0.810 | 0.806 | 0.806 | 0.954 | 0.808 | 0.958 | 12 | 14 |
| Catboost (Defaults) | 0.923 | 0.818 | 0.810 | 0.806 | 0.806 | 0.907 | 0.808 | 0.915 | 12 | 14 |
| Auto ML - Default Parameters - Scoring on ROC AUC | 0.863 | 0.811 | 0.802 | 0.800 | 0.800 | 0.846 | 0.801 | 0.851 | 13 | 14 |
| Auto ML - scoring on ROC AUC - Training for ~11 minutes | 0.884 | 0.797 | 0.787 | 0.792 | 0.792 | 0.863 | 0.789 | 0.872 | 16 | 13 |
| XGBoost | 0.979 | 0.797 | 0.788 | 0.786 | 0.786 | 0.973 | 0.787 | 0.977 | 14 | 15 |
| Decision Tree (Defaults) | 0.988 | 0.769 | 0.758 | 0.763 | 0.763 | 0.983 | 0.760 | 0.987 | 18 | 15 |
| Random Forest (Defaults) | 0.988 | 0.762 | 0.751 | 0.757 | 0.757 | 0.984 | 0.753 | 0.987 | 19 | 15 |
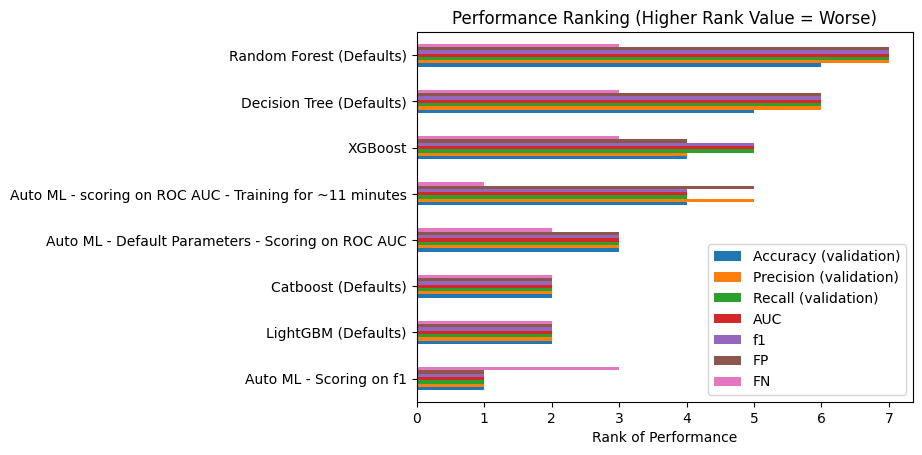
23.4.1 Ranking model performance
Let’s look at another way to quickly compare the performance of the different models.
We will rank each model by its performance against the other models, with a lower number indicating better performance relative to the other models (e.g. the model with the highest precision will be ranked 1; the model with the lowest number of false negatives will be ranked 1).
We will omit training accuracy from our calculations as we are more interested in its likely ‘real-world’ performance on unseen data.
ranking_df_high_good = results_df[['Accuracy (validation)', 'Precision (validation)', 'Recall (validation)', 'AUC', 'f1']].rank(method='dense', ascending=False).convert_dtypes()
ranking_df_low_good = results_df[['FP', 'FN']].rank(method='dense', ascending=True).convert_dtypes()
ranking_df = ranking_df_high_good.merge(ranking_df_low_good, left_index=True, right_index=True)
ranking_df['Rank Sum'] = ranking_df.sum(axis=1)
ranking_df = ranking_df.sort_values('Rank Sum', ascending=True).convert_dtypes()
ranking_df| Accuracy (validation) | Precision (validation) | Recall (validation) | AUC | f1 | FP | FN | Rank Sum | |
|---|---|---|---|---|---|---|---|---|
| Auto ML - Scoring on f1 | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 9 |
| LightGBM (Defaults) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 14 |
| Catboost (Defaults) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 14 |
| Auto ML - Default Parameters - Scoring on ROC AUC | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 20 |
| Auto ML - scoring on ROC AUC - Training for ~11 minutes | 4 | 5 | 4 | 4 | 4 | 5 | 1 | 27 |
| XGBoost | 4 | 4 | 5 | 5 | 5 | 4 | 3 | 30 |
| Decision Tree (Defaults) | 5 | 6 | 6 | 6 | 6 | 6 | 3 | 38 |
| Random Forest (Defaults) | 6 | 7 | 7 | 7 | 7 | 7 | 3 | 44 |
We could plot this output as well as everything is on the same scale (though we will omit the rank sum) as that’s much larger.
ranking_df.drop(columns="Rank Sum").plot(
kind="barh",
title="Performance Ranking (Higher Rank Value = Worse)",
xlabel="Rank of Performance"
)