# Turn warnings off to keep notebook tidy
import warnings
warnings.filterwarnings("ignore")11 Neural Networks with Tensorflow/Keras (Titanic Dataset)
TIP - this workbook contains extensive text to explain the code. To save you having to constantly scroll up and down to refer back, if you’re using VSCode you can right click on the notebook’s name tab at the top and click one of the split options (e.g. “Split Right”) to see have a second view of the same notebook that you can scroll independently.
In this workbook we build a neural network to predict passenger survival on the Titanic, using the same dataset we used for the Logistic Regression example. The two common frameworks used for neural networks are TensorFlow and PyTorch. Both are excellent frameworks. TensorFlow frequently requires fewer lines of code, but PyTorch is more natively “Pythonic” in its syntax. Here we use TensorFlow and Keras which is integrated into TensorFlow and makes it simpler and faster to build TensorFlow models.
You should install and switch to the supplied tf_hsma environment for this exercise. This environment contains an installation of TensorFlow version 2.16.1 which you will need.
11.1 The neural network unit - a neuron or perceptron
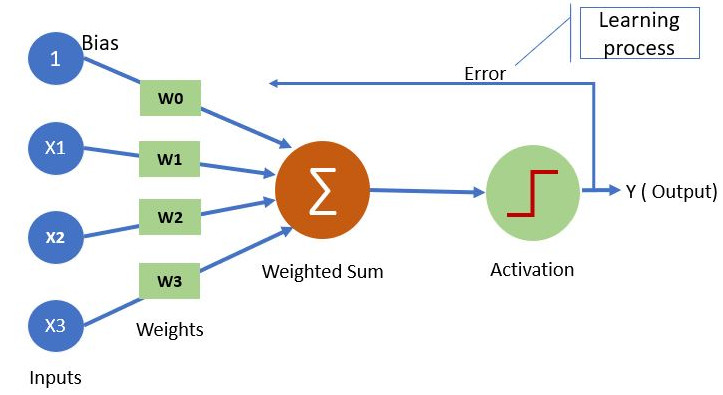
The building block of a neural network is a neuron, which is essentially the same as the ‘perceptron’ described by Frank Rosenblatt in 1958.
The neuron, or perceptron, takes inputs X and weights W (each individual input has a weight; a bias weight is also introduced by creating a dummy input with value 1). The neuron sums the input multiplied by the weight and passes the output to an activation function. The simplest activation function is a step function, whereby if the output is >0 the output of the activation function is 1, otherwise the output is 0.
11.2 Neural networks
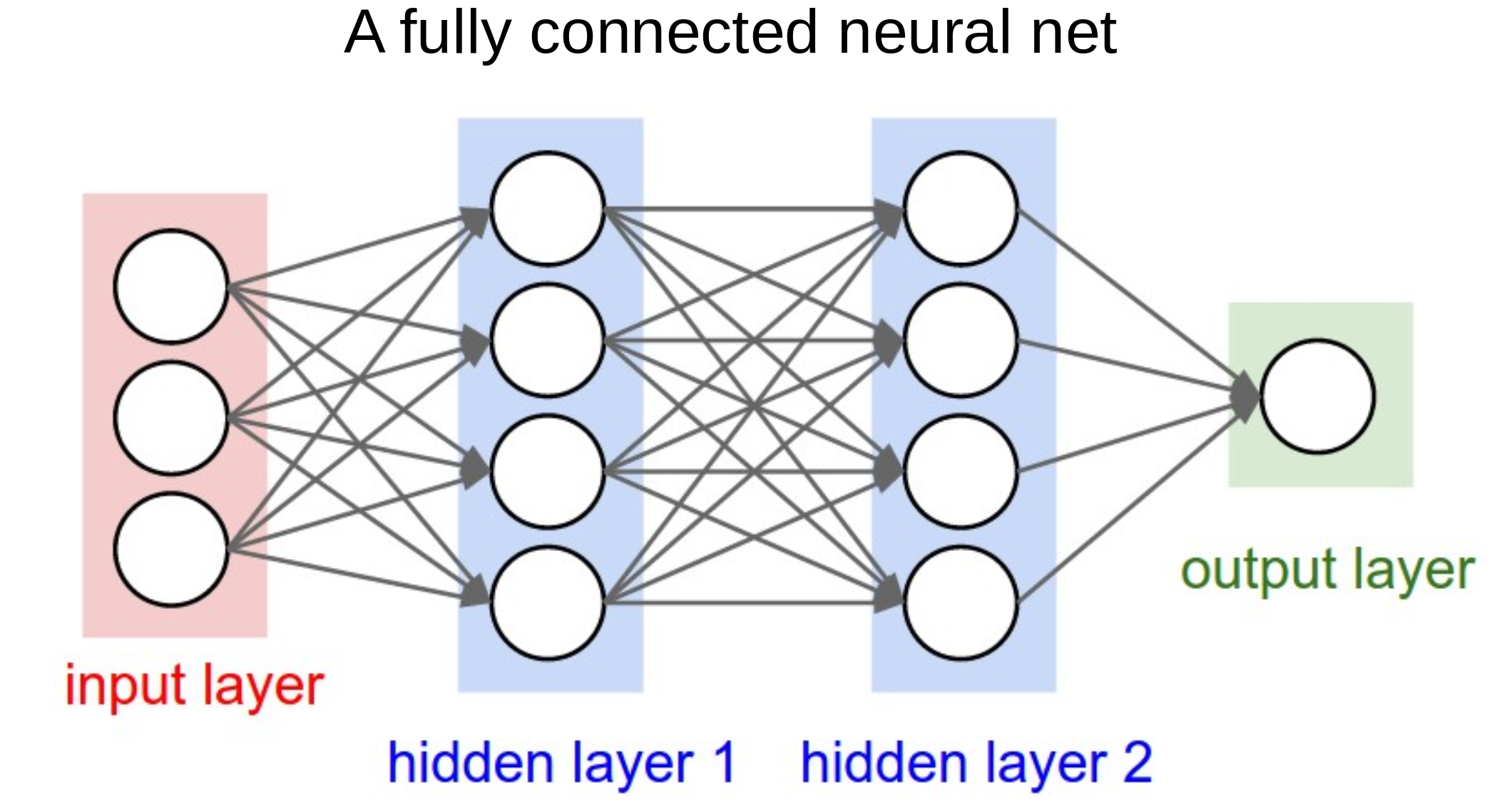
Having understood a neuron - which calculates the weighted sum of its inputs and passes it through an activation function, neural networks are easy(ish)!
They are ‘just’ a network of such neurons, where the output of one becomes one of the inputs to the neurons in the next layer.
This allows any complexity of function to be mimicked by a neural network (so long as the network includes a non-linear activation function, like ReLU - see below).
Note the output layer may be composed of a single neuron, to predict a single value or single probability, or may be multiple neurons, to predict multiple values or multiple probabilities.
11.3 Activation functions
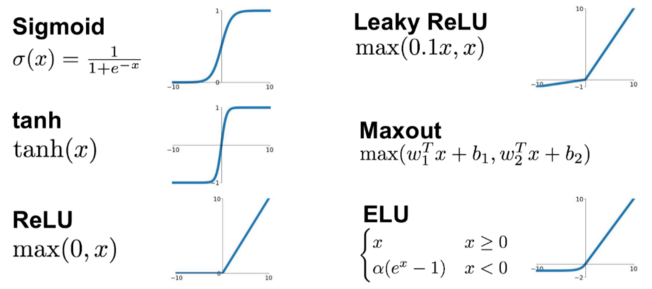
Each neuron calculates the weighted sum of its inputs and passes that sum to an activation function. The two simplest functions are:
Linear: The weighted output is passed forward with no change.
Step: The output of the activation function is 0 or 1 depending on whether a threshold is reached.
Other common activation functions are:
Sigmoid: Scales output 0-1 using a logistic function. Note that our simple single perceptron becomes a logistic regression model if we use a sigmoid activation function. The sigmoid function is often used to produce a probability output at the final layer.
tanh: Scales output -1 to 1. Commonly used in older neural network models. Not commonly used now.
ReLU (rectifying linear unit): Simply converts all negative values to zero, and leaves positive values unchanged. This very simple method is very common in deep neural networks, and is sufficient to allow networks to model non-linear functions.
Leaky ReLU and Exponential Linear Unit (ELU): Common modifications to ReLU that do not have such a hard constraint on negative inputs, and can be useful if we run into the Dying ReLU problem (in which - typically due to high learning rates - our weights are commonly set to negative values, leading to them effectively being switched off (set to 0) under ReLU). Try them out as replacements to ReLU.
Maxout: A generalised activation function that can model a complex non-linear activation function.
SoftMax: SoftMax is the final layer to use if you wish to normalise probability outputs from a network which has multiple class outputs (e.g. you want the total of your probabilities for “this is dog”, “this is a cat”, “this is a fish” etc to add up to 1).
11.4 Loss functions
Loss functions are critical to neural networks as they provide the measure by which the neural network is in error, allowing modification of the network to reduce error.
The most common loss functions are:
Mean Squared Error Loss: Common loss function for regression (predicting values rather than class).
Cross Entropy Loss: Common loss function for classification. Binary Cross Entropy Loss is used when the output is a binary classifier (like survive/die in the Titanic model).
11.5 How do neural networks learn? Backpropagation and optimisation
Backpropagation is the process by which the final loss is distributed back through the network, allowing each weight to be updated in proportion to its contribution to the final error.
For more on backpropagation see: https://youtu.be/Ilg3gGewQ5U
For deeper maths on backpropagation see: https://youtu.be/tIeHLnjs5U8
Optimisation is the step-wise process by which weights are updated. The basic underlying method, gradient descent, is that weights are adjusted in the direction that improves fit, and that weights are adjust more when the gradient (how much the output changes with each unit change to the weight) is higher.
Common optimisers used are:
Stochastic gradient descent: Updates gradients based on single samples. Can be inefficient, so can be modified to use gradients based on a small batch (e.g. 8-64) of samples. Momentum may also be added to avoid becoming trapped in local minima.
RMSprop: A ‘classic’ benchmark optimiser. Adjusts steps based on a weighted average of all weight gradients.
Adam: The most common optimiser used today. Has complex adaptive momentum for speeding up learning.
For more on optimisers see: https://youtu.be/mdKjMPmcWjY
11.6 Training a neural network - the practicalities
The training process of a neural network consists of three general phases which are repeated across all the data. All of the data is passed through the network multiple times (the number of iterations, which may be as few as 3-5 or may be 1000+) until all of the data has been fed forward and backpropogated - this then represents an “Epoch”. The three phases of an iteration are :
Pass training X data to the network and predict y
Calculate the ‘loss’ (error) between the predicted and observed (actual) values of y
Backpropagate the loss and update the weights (the job of the optimiser).
The learning is repeated until maximum accuracy is achieved (but keep an eye on accuracy of test data as well as training data as the network may develop significant over-fitting to training data unless steps are taken to offset the potential for over-fitting, such as use of ‘drop-out’ layers described below).
11.7 Architectures
The most common fully connected architecture design is to have the same number of neurons in each layer, and adjust that number and the number of layers. This makes exploring the size of the neural net relatively easy (if sometimes slow).
As a rough guide - the size of the neural net should be increased until it over-fits data (increasing accuracy of training data with reducing accuracy of test data), and then use a form of regularisation to reduce the over-fitting (we will go through this process below).
Some common architecture designs, which may be mixed in a single larger network, are:
Fully connected: The output of each neuron goes to all neurons in the next layer.
Convolutional: Common in image analysis. Small ‘mini-nets’ that look for patterns across the data - like a ‘sliding window’, but that can look at the whole picture at the same time. May also be used, for example, in time series to look for fingerprints of events anywhere in the time series.
Recurrent: Introduce the concept of some (limited) form of memory into the network - at any one time a number of input steps are affecting the network output. Useful, for example, in sound or video analysis.
Transformers: Sequence-to-sequence architecture. Convert sequences to sequences (e.g. translation). Big in Natural Language Processing - we’ll cover them in the NLP module.
Embedding: Converts a categorical value to a vector of numbers, e.g. word-2-vec converts words to vectors such that similar meaning words are positioned close together.
Encoding: Reduce many input features to fewer. This ‘compresses’ the data. De-coding layers may convert back to the original data.
Generative: Rather than regression, or classification, generative networks output some form of synthetic data (such as fake images; see https://www.thispersondoesnotexist.com/).
For the kind of classification problem we’re looking at here, a Fully Connected Neural Network is the most commonly used architecture now, and typically you keep all layers the same size (the same number of Neurons) apart from your output layer. This makes it easy to test different sizes of network.
11.8 Additional resources
Also see the excellent introductory video (20 minutes) from 3brown1blue: https://youtu.be/aircAruvnKk
11.9 Let’s go !!!!!!!!!!!!!
In this first cell, we’re going to be a bit naughty, and turn off warnings (such as “you’re using an out-of-date version of this” etc). This will make the notebook cleaner and easier to interpret as you learn this, but in real-world work you shouldn’t really do this unless you know what you’re doing. But we’ll do it here because we do (I think).
Don’t forget to select the tf_hsma environment when you run the first cell. If you’re prompted that you need to install the ipykernel, click that you want to do it.
11.10 Load modules
First we need to import the packages we’re going to use. The first three (MatPlotLib, NumPy and Pandas) are the stuff we use in pretty much everything in data science. From SciKitLearn, we import functions to automatically split our data into training and test data (as we did for the Logistic Regression example) and to min-max normalise our data (remember we said that normalising our data is typical with Neural Networks (“Neural Networks are Normal”), and standardising our data - what we did last time - is typical with Logistic Regression). Remember, when we normalise we’ll scale all our feature values so they fall between 0 and 1.
Then, we import a load of things we’ll need from TensorFlow (and particularly Keras). TensorFlow is the Neural Network architecture developed by Google, but the interface (API) for TensorFlow is not easy to use. So instead, we use Keras, which sits on top of TensorFlow, and allows us to interact with TensorFlow in a much more straightforward way. Don’t worry about what each of things that we import are at this stage - we’ll see them in use as we move through the notebook.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# sklearn for pre-processing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# TensorFlow sequential model
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.optimizers import Adam11.11 Download data if not previously downloaded
This cell downloads the Titanic data that we’re going to use. You don’t need to do this if you’ve already downloaded the data, but if you’re unsure, run the cell anyway (it takes seconds!).
download_required = True
if download_required:
# Download processed data:
address = 'https://raw.githubusercontent.com/MichaelAllen1966/' + \
'1804_python_healthcare/master/titanic/data/processed_data.csv'
data = pd.read_csv(address)
# Create a data subfolder if one does not already exist
import os
data_directory ='./data/'
if not os.path.exists(data_directory):
os.makedirs(data_directory)
# Save data
data.to_csv(data_directory + 'processed_data.csv', index=False)11.12 Define function to scale data
In neural networks it is common to normalise (scale input data 0-1) rather than use standardise (subtracting mean and dividing by standard deviation) each feature. As with the Logistic Regression example, we’ll set up a function here that we can call whenever we want to do this (the only difference being that in the Logistic Regression example we standardised our data, rather than normalising it).
def scale_data(X_train, X_test):
"""Scale data 0-1 based on min and max in training set"""
# Initialise a new scaling object for normalising input data
sc = MinMaxScaler()
# Apply the scaler to the training and test sets
train_sc = sc.fit_transform(X_train)
test_sc = sc.fit_transform(X_test)
return train_sc, test_sc11.13 Load data
We’re going to load up and do a bit of initial prep on our data, much as we did before for the Logistic Regression. We’re going to load our data (which is stored in a .csv file) into a Pandas DataFrame. We’ll convert all the data into floating point numbers so everything is consistent. We’ll drop the Passenger ID column, as that isn’t part of the original data, and we don’t want the machine to learn anything from this.
Then we define our input (X) and output (y) data. Remember we’re trying to predict y from X. X is all of our columns (features) except for the “Survived” column (which is our label - the thing we’re trying to predict). The axis=1 argument tells Pandas we’re referring to columns when we tell it to drop stuff.
We also set up NumPy versions of our X and y data - this is a necessary step if we were going to do k-fold splits (remember we talked about those in the last session - it’s where we split up our data into training and test sets in multiple different ways to try to avoid biasing the data) as it requires the data to be in NumPy arrays, not Pandas DataFrames. We’re not actually going to use k-fold splits in this workbook, but we’ll still go through the step of getting the data into the right format for when we do. Because, in real world applications, you should use k-fold splits.
data = pd.read_csv('data/processed_data.csv')
# Make all data 'float' type
data = data.astype(float)
data.drop('PassengerId', inplace=True, axis=1)
X = data.drop('Survived',axis=1) # X = all 'data' except the 'survived' column
y = data['Survived'] # y = 'survived' column from 'data'
# Convert to NumPy as required for k-fold splits
X_np = X.values
y_np = y.values12 Set up neural net
We’re going to put construction of the neural net into a separate function, which is what we’ve written in this next cell. The function that we’ve written will build a network of any size, but the one we set up here will be relatively simple. As you read each bit in this description, you should scroll down to look at the corresponding code in the next cell.
Here we use the sequential method to set up a TensorFlow neural network. This simpler method assumes each layer of the Neural Network occurs in sequence (one layer of neurons feeds into the next layer of neurons etc). There are more complex architectures, but the simple sequential architecture is common. Though simpler, it lacks some flexibility. But don’t worry about that for the moment.
The inputs into the function are as follows :
- The number of features in our input data (the columns of data from which we hope to make a prediction)
- The number of hidden layers - these are the layers between our input layer and our output layer. Determining how many works best for your problem is a bit of an art-form, but you’ll probably find something between 1 and 7 hidden layers works well for classification problems. We set a default of 3, so if we don’t specify a number when calling the function, it’ll default to 3 hidden layers. (The assignment operator
=denotes we are specifying a default value) - The number of neurons in each hidden layer. We default to 128 if no number is specified when the function is called.
- The dropout rate (the proportion of neurons that will be randomly “switched off” in each epoch to try to prevent overfitting. We default to no dropout if no value is specified when the function is called.
- A learning rate, that will be used by the optimiser to determine how much it should change each time in response to the estimated error. In other words, how sensitive will it be. As with most things in a Neural Network, you will spend a lot of time playing around with these parameters to see if it improves things, but a good default is 0.003 (although for some non-Adam optimisers, that can be considered quite high, so you might want to try much lower learning rates to see if they help). We use 0.003 as the default if no value is specified when the function is called.
In the function, we first clear the session. There used to be issues with TensorFlow keeping old models hanging around in memory - whilst it probably isn’t an issue now, we still do it just to be on the safe side.
Then we create a new Sequential Neural Network.
Next, we use a loop to set up the hidden layers of our network (the input layer is added automatically and we don’t need to explicitly define it). For each pass of the for loop (you’ll see we go around the loop the number of times we have passed in as being the number of hidden layers we want) we :
- Add a fully-connected (dense) layer (one in which all of the neurons in the layer are connected to all of the neurons in the next layer), using the ReLU activation function for its neurons (you could of course change this to another activation function of your choosing)
- Add a dropout layer, to enable dropout
So, we end up with a set of fully-connected layers, each with a dropout layer after it.
Once we’ve added all our hidden layers we then add our final output layer. Here, we add a densely connected output layer with 1 neuron (which will calculate the output - the prediction) using the Sigmoid activation function (because we want our output to be a kind of “likelihood” of it being a classified as a ‘1’ - whatever that represents in our model. By default, anything over 0.5 will be classified as 1, whilst everything else will be classified as 0). Note of caution - do not interpret this number as being a probability that something belongs to a certain class, it’s subtly different (so for example, you shouldn’t see that a passenger has an output value of 0.6, and interpret that that they had a 60% probability of survival. That’s NOT correct. Rather, the model has classified them as likely a survivor with a small amount of confidence (it’s only just past the threshold of 0.5)).
Next we add our optimiser engine. Remember - if in doubt, use Adam :)
Then we “compile” the Neural Network (this is just a fancy way of saying we’ll tell TensorFlow to build what we’ve set up above). When we tell it to compile, we tell it the loss function we want to use (here - binary crossentropy, because it’s a classification problem with two possible outputs - for the Titanic problem, this is “survived” or “died”). We also specify the metrics that we want TensorFlow to monitor as the model is being “fitted” (learning) - here we tell it to monitor accuracy.
Finally, we get the function to return the network so we can use it (remember - the purpose of this function is to build a network to our specifications when we call it).
def make_net(number_features,
hidden_layers=3,
hidden_layer_neurones=128,
dropout=0.0,
learning_rate=0.003):
"""Make TensorFlow neural net"""
# Clear Tensorflow
K.clear_session()
# Set up neural net
net = Sequential()
# Add hidden hidden_layers using a loop
for i in range(hidden_layers):
# Add fully connected layer with ReLu activation
net.add(Dense(
hidden_layer_neurones,
input_dim=number_features,
activation='relu'))
# Add droput layer
net.add(Dropout(dropout))
# Add final sigmoid activation output
net.add(Dense(1, activation='sigmoid'))
# Compiling model
opt = Adam(learning_rate=learning_rate)
net.compile(loss='binary_crossentropy',
optimizer=opt,
metrics=['accuracy'])
return net12.1 Show summary of the model structure
Here we will create an arbitrary model (that we won’t use) with 10 input features, just to show the function we wrote above being used and so you can see how you can use the summary() function of a model to see an overview of the structure of it.
We can see what the layers are in order. Remember we have five main layers in total (input, 3 x hidden, output) but you won’t see the input layer here. When you run the below cell, you should see three hidden layers (each with a dropout layer immediately after) with 128 neurons in each layer followed by a final output layer with just one neuron. You’ll also see that there are over 34,500 parameters (weights) that it needs to optimise, just in a very simple network like this on a very small dataset with 10 features. Now you can see why they’re so complicated (and magical!).
model = make_net(10)
model.summary()WARNING:tensorflow:From c:\Users\Sammi\Anaconda3\envs\ml_sammi\Lib\site-packages\keras\src\backend\common\global_state.py:82: The name tf.reset_default_graph is deprecated. Please use tf.compat.v1.reset_default_graph instead.
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 128) │ 1,408 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 128) │ 16,512 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_1 (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 128) │ 16,512 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_2 (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_3 (Dense) │ (None, 1) │ 129 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 34,561 (135.00 KB)
Trainable params: 34,561 (135.00 KB)
Non-trainable params: 0 (0.00 B)
12.2 Split and Scale data
Now, as we did before with the Logistic Regression, we split our data into training and test sets. We’ve got 25% carved off for our test set. But what is this random_state=42 thing? So, pulling back the curtain now, but the random numbers we tend to generate in our computers are not strictly random. They are pseudo-random - they use complex algorithms to generate numbers that appear random (and which are good enough for the vast majority of things you will ever do). Because they are pseudo-random, this means that we can fix the random number generator to use a pre-defined seed - a number that feeds into the algorithm which will ensure we always get the same random numbers being generated. This can be useful if we’re 1) teaching, and you want everyone to get the same thing, or 2) validating our outputs whilst we build our model. Since we’re doing both of those things here, we use a fixed seed.
But why the number 42? Those of you who have read, watched and / or listened to The Hitchiker’s Guide to the Galaxy will know why. Those that haven’t, go off and read, watch or listen to it and then you’ll get the “joke” (Computer Scientists love doing stuff like this..)
Once we’ve established our training and testing data, we scale the data by normalising it, using the function we wrote earlier (which uses min-max normalisation).
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X_np, y_np, test_size = 0.25, random_state=42)
# Scale X data
X_train_sc, X_test_sc = scale_data(X_train, X_test)Let’s just have a look at the scaled data for the first two records (passengers) in our input data. We should see that all of the feature values have scaled between 0 and 1.
X_train_sc[0:2]array([[0. , 0.34656949, 0. , 0. , 0.05953204,
1. , 0. , 0. , 0.828125 , 0. ,
1. , 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. ,
0. , 0. , 0. , 0. ],
[1. , 0.30887158, 0. , 0. , 0.01376068,
0. , 0. , 1. , 0. , 1. ,
1. , 0. , 0. , 1. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. ]])We can compare this with the unscaled data for the same two passengers to see the original values.
X_train[0:2]array([[ 1. , 28. , 0. , 0. , 30.5 , 1. , 0. , 0. ,
106. , 0. , 1. , 0. , 0. , 1. , 0. , 0. ,
0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. ],
[ 3. , 25. , 0. , 0. , 7.05, 0. , 0. , 1. ,
0. , 1. , 1. , 0. , 0. , 1. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 1. ]])12.3 Function to calculate accuracy
We’re now going to write a little function that will report the accuracy of the model on the training set and the test set. This will help us assess how well our model is performing. We pass into the function the model, the (normalised) input data for both the training and test sets, and the output data for both the training and test sets.
The function uses the predict function of the model to grab out the probability predictions based on the input data for the training set. We specify that a classification of 1 (in the case of Titanic, this means “survived”) should be made if the probability predicted is greater than 0.5. Then we “flatten” the data to get it in the right shape (because it comes out as a complex shape - a tensor. Don’t worry about this. Just imagine a blob of data, and we squish it so we can read it). Then we use y_pred_train == y_train to return boolean True values for each time where the prediction (survived or died) matched the real answer, and take the average of those matches (that effectively gives us accuracy - what proportion of times did prediction match real answer). (Python interprets Trues and Falses as 1s and 0s, in case you’re wondering how that works!).
Then we do the same as above but for the test set.
Finally we print the accuracy on both the training and test sets.
def calculate_accuracy(model, X_train_sc, X_test_sc, y_train, y_test):
"""Calculate and print accuracy of training and test data fits"""
### Get accuracy of fit to training data
probability = model.predict(X_train_sc)
y_pred_train = probability >= 0.5
y_pred_train = y_pred_train.flatten()
accuracy_train = np.mean(y_pred_train == y_train)
### Get accuracy of fit to test data
probability = model.predict(X_test_sc)
y_pred_test = probability >= 0.5
y_pred_test = y_pred_test.flatten()
accuracy_test = np.mean(y_pred_test == y_test)
# Show acuracy
print (f'Training accuracy {accuracy_train:0.3f}')
print (f'Test accuracy {accuracy_test:0.3f}')We’ll also write a little function to plot the accuracy on the training set and the test set over time. Keras keeps a “history” (which is a dictionary) of the learning which allows us to do this easily. It’s quite useful to plot the performance over time, as it allows us to look for indications as to when the model is becoming overfitted etc.
In our function, we’ll grab out the values from the passed in history dictionary, and then plot them using standard matplotlib plotting methods.
def plot_training(history_dict):
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
epochs = range(1, len(acc_values) + 1)
fig, ax = plt.subplots()
ax.set_xlabel('Time')
ax.set_ylabel('Accuracy')
ax.plot(epochs, acc_values, color='blue', label='Training acc')
ax.plot(epochs, val_acc_values, color='red', label='Test accuracy')
ax.set_title('Training and validation accuracy')
ax.legend()
fig.show()12.4 Run the model
We’ve now defined everything that will allow us to build the model. So we’ll now define the model we want and train it!
To work out how many features we need (which we then need to pass into the make_net function we defined earlier), we can simply look at the number of columns in our X (input) data (where we’ve removed the ‘label’ (output) column). We can grab this from the standardised training data, by looking at index 1 of the shape tuple (index 0 would be rows (passengers in the Titanic data), and index 1 would be columns). We can see this if we run the code X_train_sc.shape. Try it yourself (just insert a code cell below this markdown cell)! You should see there are 668 rows, and 24 columns. Therefore, we’ve got 668 passengers and 24 features.
Next we call our make_net function, passing in the number of features we calculated above. This will create our Neural Network. As we’ve passed in nothing else, we’ll have defaults for the rest of the network - 3 hidden layers, 128 neurons per layer, a learning rate of 0.003 and no dropout (although, we will still have dropput layers, they just won’t do anything).
Then, we fit (train) the model. To do that, we call the fit method of the model, and pass it :
- the standardised training data
- the output (label) data
- the number of epochs (training generations - full passes of all of the data through the network). Initially, we want enough epochs that we see overfitting start to happen (the training accuracy starts to plateau) because then we know we’ve trained “enough” (albeit a bit too much) and can then look to reduce it back a bit
- the batch size (how much data we shunt through the network at once. Yann LeCun (French Computer Scientist) advises “Friends shouldn’t let friends use batch sizes of more than 32”. But we will here… :))
- the data we want to use as our “validation data” (which we use to fine tune the parameters of the model). Keras will check performance on this validation data. Here we just use our test set, but you should really have a separate “validation set” that you’d use whilst tuning the model.
- whether we want to see all the things it’s doing as it’s learning. If we set
verboseto 0, all of this will be hidden (keeping things tidier), but as we’re experimenting with our model, it’s a good idea to setverboseto 1 so we can monitor what it’s doing.
You’ll also see that we not only call model.fit but we store the output of that function in a variable called history. This allows us to access all the useful information that keras was keeping track of whilst the model was training. We’ll use that later.
Note - when you run the cell below, the model will be built and then start training. How long this takes will depend on your computer specs, including whether you have a CUDA-enabled GPU (if you’re running locally) or your priority in the queue for cloud computing (if you’re running this on CoLab).
Dan has a very fast computer with a high performance CUDA-enabled GPU, and the below (with 250 epochs) takes about 6 seconds on the GPU and about 11 seconds on the CPU. It might take a little while longer on yours - don’t worry, as long as you can see it moving through the epochs.
For each epoch, you’ll see various information, including the epoch number, the loss (error) that’s been calculated in that epoch (for both the training and validation data), and the accuracy (for both the training and validation data). You should see loss gradually reduce, and accuracy gradually increase. But you’ll likely see that training accuracy tends to keep getting better (before it reaches a plateau) and validation accuracy gets better but then starts to drop a bit. That’s a sign of overfitting (our model’s become increasingly brilliant for the training data, but starting to get increasingly rubbish at being more generally useful).
# Define network
number_features = X_train_sc.shape[1]
model = make_net(number_features)
### Train model (and store training info in history)
history = model.fit(X_train_sc,
y_train,
epochs=250,
batch_size=64,
validation_data=(X_test_sc, y_test),
verbose=1)Epoch 1/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 1s 15ms/step - accuracy: 0.5894 - loss: 0.6207 - val_accuracy: 0.7489 - val_loss: 0.5343
Epoch 2/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.7645 - loss: 0.5116 - val_accuracy: 0.7803 - val_loss: 0.4798
Epoch 3/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.7654 - loss: 0.4894 - val_accuracy: 0.8117 - val_loss: 0.4555
Epoch 4/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8346 - loss: 0.4073 - val_accuracy: 0.8027 - val_loss: 0.4448
Epoch 5/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8469 - loss: 0.4044 - val_accuracy: 0.7758 - val_loss: 0.5106
Epoch 6/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8175 - loss: 0.4148 - val_accuracy: 0.8117 - val_loss: 0.4318
Epoch 7/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8279 - loss: 0.3935 - val_accuracy: 0.8027 - val_loss: 0.4375
Epoch 8/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8366 - loss: 0.4046 - val_accuracy: 0.8027 - val_loss: 0.4640
Epoch 9/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8236 - loss: 0.4184 - val_accuracy: 0.8072 - val_loss: 0.4712
Epoch 10/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8344 - loss: 0.3743 - val_accuracy: 0.8072 - val_loss: 0.4901
Epoch 11/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8338 - loss: 0.3994 - val_accuracy: 0.8072 - val_loss: 0.4832
Epoch 12/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8273 - loss: 0.3678 - val_accuracy: 0.8206 - val_loss: 0.4622
Epoch 13/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8438 - loss: 0.3705 - val_accuracy: 0.7937 - val_loss: 0.5043
Epoch 14/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8478 - loss: 0.3726 - val_accuracy: 0.7982 - val_loss: 0.5243
Epoch 15/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8387 - loss: 0.3699 - val_accuracy: 0.8251 - val_loss: 0.5106
Epoch 16/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8551 - loss: 0.3550 - val_accuracy: 0.7578 - val_loss: 0.4942
Epoch 17/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8415 - loss: 0.3626 - val_accuracy: 0.7848 - val_loss: 0.5928
Epoch 18/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8400 - loss: 0.3567 - val_accuracy: 0.8161 - val_loss: 0.4823
Epoch 19/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8661 - loss: 0.3454 - val_accuracy: 0.8117 - val_loss: 0.5576
Epoch 20/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8629 - loss: 0.3278 - val_accuracy: 0.8206 - val_loss: 0.5223
Epoch 21/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8526 - loss: 0.3550 - val_accuracy: 0.8117 - val_loss: 0.5888
Epoch 22/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8647 - loss: 0.3301 - val_accuracy: 0.8206 - val_loss: 0.5603
Epoch 23/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8622 - loss: 0.3260 - val_accuracy: 0.8072 - val_loss: 0.6828
Epoch 24/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8717 - loss: 0.3087 - val_accuracy: 0.8251 - val_loss: 0.5943
Epoch 25/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8460 - loss: 0.3446 - val_accuracy: 0.8027 - val_loss: 0.6073
Epoch 26/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8601 - loss: 0.3467 - val_accuracy: 0.8161 - val_loss: 0.6106
Epoch 27/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8680 - loss: 0.3236 - val_accuracy: 0.8072 - val_loss: 0.5850
Epoch 28/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8689 - loss: 0.3169 - val_accuracy: 0.7803 - val_loss: 0.7162
Epoch 29/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8634 - loss: 0.3264 - val_accuracy: 0.8161 - val_loss: 0.6224
Epoch 30/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8903 - loss: 0.2943 - val_accuracy: 0.8117 - val_loss: 0.6422
Epoch 31/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9017 - loss: 0.2637 - val_accuracy: 0.7892 - val_loss: 0.7711
Epoch 32/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8693 - loss: 0.3187 - val_accuracy: 0.7848 - val_loss: 0.6392
Epoch 33/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8680 - loss: 0.3148 - val_accuracy: 0.8072 - val_loss: 0.6474
Epoch 34/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8742 - loss: 0.3211 - val_accuracy: 0.8117 - val_loss: 0.7169
Epoch 35/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8721 - loss: 0.3133 - val_accuracy: 0.8251 - val_loss: 0.7245
Epoch 36/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8893 - loss: 0.3021 - val_accuracy: 0.7982 - val_loss: 0.7685
Epoch 37/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9001 - loss: 0.2708 - val_accuracy: 0.8027 - val_loss: 0.8393
Epoch 38/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8821 - loss: 0.2675 - val_accuracy: 0.7982 - val_loss: 0.7583
Epoch 39/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.8499 - loss: 0.3350 - val_accuracy: 0.7982 - val_loss: 0.9216
Epoch 40/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8934 - loss: 0.2763 - val_accuracy: 0.7803 - val_loss: 0.7980
Epoch 41/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8644 - loss: 0.3112 - val_accuracy: 0.8027 - val_loss: 0.8078
Epoch 42/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8864 - loss: 0.2734 - val_accuracy: 0.7982 - val_loss: 0.9689
Epoch 43/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8827 - loss: 0.3064 - val_accuracy: 0.8027 - val_loss: 0.8839
Epoch 44/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9008 - loss: 0.2696 - val_accuracy: 0.8027 - val_loss: 0.8412
Epoch 45/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8761 - loss: 0.3005 - val_accuracy: 0.7892 - val_loss: 1.1601
Epoch 46/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8918 - loss: 0.3082 - val_accuracy: 0.8072 - val_loss: 0.7309
Epoch 47/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8803 - loss: 0.2903 - val_accuracy: 0.7758 - val_loss: 0.7280
Epoch 48/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8889 - loss: 0.2922 - val_accuracy: 0.7982 - val_loss: 0.7266
Epoch 49/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8941 - loss: 0.2913 - val_accuracy: 0.7848 - val_loss: 0.8113
Epoch 50/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8766 - loss: 0.2874 - val_accuracy: 0.8117 - val_loss: 0.7758
Epoch 51/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8967 - loss: 0.2838 - val_accuracy: 0.7803 - val_loss: 0.8528
Epoch 52/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8900 - loss: 0.2808 - val_accuracy: 0.7937 - val_loss: 0.8781
Epoch 53/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8819 - loss: 0.2898 - val_accuracy: 0.8027 - val_loss: 0.9223
Epoch 54/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8991 - loss: 0.2740 - val_accuracy: 0.8027 - val_loss: 0.9023
Epoch 55/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8974 - loss: 0.2591 - val_accuracy: 0.7848 - val_loss: 1.0537
Epoch 56/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8879 - loss: 0.2733 - val_accuracy: 0.8027 - val_loss: 0.9573
Epoch 57/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9012 - loss: 0.2500 - val_accuracy: 0.7982 - val_loss: 0.9256
Epoch 58/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.8798 - loss: 0.2910 - val_accuracy: 0.7982 - val_loss: 0.9879
Epoch 59/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9055 - loss: 0.2531 - val_accuracy: 0.7848 - val_loss: 1.0956
Epoch 60/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8856 - loss: 0.2910 - val_accuracy: 0.8027 - val_loss: 0.9856
Epoch 61/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8928 - loss: 0.2812 - val_accuracy: 0.8117 - val_loss: 0.9860
Epoch 62/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8784 - loss: 0.2847 - val_accuracy: 0.7892 - val_loss: 1.0311
Epoch 63/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8993 - loss: 0.2482 - val_accuracy: 0.8161 - val_loss: 1.0434
Epoch 64/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8928 - loss: 0.2728 - val_accuracy: 0.7892 - val_loss: 0.9807
Epoch 65/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9025 - loss: 0.2681 - val_accuracy: 0.8027 - val_loss: 1.0414
Epoch 66/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8994 - loss: 0.2493 - val_accuracy: 0.8117 - val_loss: 1.0447
Epoch 67/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8953 - loss: 0.2612 - val_accuracy: 0.8027 - val_loss: 1.0741
Epoch 68/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9051 - loss: 0.2460 - val_accuracy: 0.8161 - val_loss: 1.1610
Epoch 69/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8952 - loss: 0.2547 - val_accuracy: 0.8027 - val_loss: 1.1435
Epoch 70/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8987 - loss: 0.2439 - val_accuracy: 0.8206 - val_loss: 1.1246
Epoch 71/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9031 - loss: 0.2437 - val_accuracy: 0.8072 - val_loss: 1.1499
Epoch 72/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8842 - loss: 0.2726 - val_accuracy: 0.8117 - val_loss: 1.1043
Epoch 73/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8934 - loss: 0.2641 - val_accuracy: 0.8027 - val_loss: 1.1882
Epoch 74/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8886 - loss: 0.2595 - val_accuracy: 0.7937 - val_loss: 1.1686
Epoch 75/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8918 - loss: 0.2583 - val_accuracy: 0.8027 - val_loss: 1.1956
Epoch 76/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9068 - loss: 0.2362 - val_accuracy: 0.8117 - val_loss: 1.1993
Epoch 77/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8918 - loss: 0.2342 - val_accuracy: 0.8251 - val_loss: 1.2751
Epoch 78/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9055 - loss: 0.2424 - val_accuracy: 0.7937 - val_loss: 1.3184
Epoch 79/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8898 - loss: 0.2682 - val_accuracy: 0.8161 - val_loss: 1.2269
Epoch 80/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8871 - loss: 0.2632 - val_accuracy: 0.8117 - val_loss: 1.2805
Epoch 81/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8793 - loss: 0.2542 - val_accuracy: 0.8206 - val_loss: 1.2283
Epoch 82/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9033 - loss: 0.2421 - val_accuracy: 0.7713 - val_loss: 1.5658
Epoch 83/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8944 - loss: 0.2464 - val_accuracy: 0.8117 - val_loss: 1.3082
Epoch 84/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8859 - loss: 0.2661 - val_accuracy: 0.8117 - val_loss: 1.3584
Epoch 85/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9031 - loss: 0.2413 - val_accuracy: 0.8117 - val_loss: 1.1927
Epoch 86/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9046 - loss: 0.2347 - val_accuracy: 0.7848 - val_loss: 1.6775
Epoch 87/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8836 - loss: 0.2844 - val_accuracy: 0.8027 - val_loss: 1.4149
Epoch 88/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8927 - loss: 0.2857 - val_accuracy: 0.8206 - val_loss: 0.9820
Epoch 89/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8876 - loss: 0.2678 - val_accuracy: 0.7937 - val_loss: 1.1708
Epoch 90/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8873 - loss: 0.3120 - val_accuracy: 0.8117 - val_loss: 1.0113
Epoch 91/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9057 - loss: 0.2408 - val_accuracy: 0.7937 - val_loss: 1.0703
Epoch 92/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9058 - loss: 0.2399 - val_accuracy: 0.8027 - val_loss: 1.0774
Epoch 93/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9008 - loss: 0.2366 - val_accuracy: 0.8027 - val_loss: 1.0887
Epoch 94/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8977 - loss: 0.2540 - val_accuracy: 0.7848 - val_loss: 1.2006
Epoch 95/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8891 - loss: 0.2580 - val_accuracy: 0.7937 - val_loss: 1.1843
Epoch 96/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9007 - loss: 0.2438 - val_accuracy: 0.8161 - val_loss: 1.0627
Epoch 97/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8920 - loss: 0.2779 - val_accuracy: 0.8072 - val_loss: 1.1149
Epoch 98/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9096 - loss: 0.2227 - val_accuracy: 0.8027 - val_loss: 1.1924
Epoch 99/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9080 - loss: 0.2331 - val_accuracy: 0.7937 - val_loss: 1.1596
Epoch 100/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9054 - loss: 0.2379 - val_accuracy: 0.8027 - val_loss: 1.2739
Epoch 101/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9096 - loss: 0.2241 - val_accuracy: 0.8117 - val_loss: 1.2690
Epoch 102/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9056 - loss: 0.2272 - val_accuracy: 0.8161 - val_loss: 1.2559
Epoch 103/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8976 - loss: 0.2425 - val_accuracy: 0.8161 - val_loss: 1.2372
Epoch 104/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9137 - loss: 0.2138 - val_accuracy: 0.8027 - val_loss: 1.3317
Epoch 105/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8869 - loss: 0.2747 - val_accuracy: 0.8072 - val_loss: 1.3751
Epoch 106/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9027 - loss: 0.2292 - val_accuracy: 0.7982 - val_loss: 1.3915
Epoch 107/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9002 - loss: 0.2418 - val_accuracy: 0.7982 - val_loss: 1.3141
Epoch 108/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9095 - loss: 0.2260 - val_accuracy: 0.8117 - val_loss: 1.3647
Epoch 109/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9018 - loss: 0.2362 - val_accuracy: 0.8027 - val_loss: 1.3624
Epoch 110/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9090 - loss: 0.2283 - val_accuracy: 0.8027 - val_loss: 1.3470
Epoch 111/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9253 - loss: 0.1949 - val_accuracy: 0.8072 - val_loss: 1.4330
Epoch 112/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8980 - loss: 0.2377 - val_accuracy: 0.8027 - val_loss: 1.4227
Epoch 113/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9182 - loss: 0.2017 - val_accuracy: 0.7982 - val_loss: 1.4266
Epoch 114/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9243 - loss: 0.1946 - val_accuracy: 0.8072 - val_loss: 1.4049
Epoch 115/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9201 - loss: 0.2086 - val_accuracy: 0.8117 - val_loss: 1.5301
Epoch 116/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9081 - loss: 0.2193 - val_accuracy: 0.8072 - val_loss: 1.4580
Epoch 117/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9265 - loss: 0.1897 - val_accuracy: 0.8117 - val_loss: 1.6142
Epoch 118/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9002 - loss: 0.2341 - val_accuracy: 0.8117 - val_loss: 1.4237
Epoch 119/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9007 - loss: 0.2468 - val_accuracy: 0.8072 - val_loss: 1.4527
Epoch 120/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9050 - loss: 0.2552 - val_accuracy: 0.7982 - val_loss: 1.4548
Epoch 121/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9180 - loss: 0.2204 - val_accuracy: 0.8072 - val_loss: 1.5674
Epoch 122/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8948 - loss: 0.2526 - val_accuracy: 0.8206 - val_loss: 1.4663
Epoch 123/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9069 - loss: 0.2285 - val_accuracy: 0.7982 - val_loss: 1.6611
Epoch 124/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9029 - loss: 0.2316 - val_accuracy: 0.8027 - val_loss: 1.4079
Epoch 125/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9042 - loss: 0.2263 - val_accuracy: 0.8027 - val_loss: 1.5330
Epoch 126/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9162 - loss: 0.2163 - val_accuracy: 0.8296 - val_loss: 1.5034
Epoch 127/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9054 - loss: 0.2326 - val_accuracy: 0.8161 - val_loss: 1.4424
Epoch 128/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9115 - loss: 0.2303 - val_accuracy: 0.7848 - val_loss: 1.5685
Epoch 129/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9084 - loss: 0.2286 - val_accuracy: 0.8161 - val_loss: 1.5663
Epoch 130/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9012 - loss: 0.2440 - val_accuracy: 0.8251 - val_loss: 1.6786
Epoch 131/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9033 - loss: 0.2283 - val_accuracy: 0.8027 - val_loss: 1.6477
Epoch 132/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9100 - loss: 0.2287 - val_accuracy: 0.8027 - val_loss: 1.5885
Epoch 133/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9024 - loss: 0.2255 - val_accuracy: 0.8072 - val_loss: 1.5587
Epoch 134/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9128 - loss: 0.2038 - val_accuracy: 0.7803 - val_loss: 1.7733
Epoch 135/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9135 - loss: 0.2249 - val_accuracy: 0.8206 - val_loss: 1.4879
Epoch 136/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8921 - loss: 0.2508 - val_accuracy: 0.8161 - val_loss: 1.5537
Epoch 137/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9112 - loss: 0.2282 - val_accuracy: 0.7982 - val_loss: 1.7163
Epoch 138/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9134 - loss: 0.1975 - val_accuracy: 0.8072 - val_loss: 1.6882
Epoch 139/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9144 - loss: 0.2140 - val_accuracy: 0.8027 - val_loss: 1.7327
Epoch 140/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9187 - loss: 0.1955 - val_accuracy: 0.8161 - val_loss: 1.6430
Epoch 141/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9207 - loss: 0.2046 - val_accuracy: 0.8117 - val_loss: 1.6671
Epoch 142/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9009 - loss: 0.2251 - val_accuracy: 0.7937 - val_loss: 1.7145
Epoch 143/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9103 - loss: 0.2087 - val_accuracy: 0.8117 - val_loss: 1.7463
Epoch 144/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9042 - loss: 0.2122 - val_accuracy: 0.8161 - val_loss: 1.6424
Epoch 145/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9137 - loss: 0.2045 - val_accuracy: 0.8027 - val_loss: 1.8534
Epoch 146/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9114 - loss: 0.2300 - val_accuracy: 0.8296 - val_loss: 1.6790
Epoch 147/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9051 - loss: 0.2112 - val_accuracy: 0.8072 - val_loss: 1.7015
Epoch 148/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8965 - loss: 0.2250 - val_accuracy: 0.8206 - val_loss: 1.6936
Epoch 149/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9083 - loss: 0.2216 - val_accuracy: 0.8206 - val_loss: 1.7359
Epoch 150/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9207 - loss: 0.2102 - val_accuracy: 0.8251 - val_loss: 1.7592
Epoch 151/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9028 - loss: 0.2250 - val_accuracy: 0.7982 - val_loss: 1.8319
Epoch 152/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9255 - loss: 0.1886 - val_accuracy: 0.8117 - val_loss: 1.8389
Epoch 153/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9227 - loss: 0.1878 - val_accuracy: 0.8117 - val_loss: 1.8696
Epoch 154/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9283 - loss: 0.1935 - val_accuracy: 0.8117 - val_loss: 1.8943
Epoch 155/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9197 - loss: 0.2009 - val_accuracy: 0.8117 - val_loss: 1.8556
Epoch 156/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9152 - loss: 0.1983 - val_accuracy: 0.8341 - val_loss: 1.8383
Epoch 157/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9130 - loss: 0.2079 - val_accuracy: 0.7892 - val_loss: 1.9779
Epoch 158/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9167 - loss: 0.1999 - val_accuracy: 0.8161 - val_loss: 1.9083
Epoch 159/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9226 - loss: 0.1932 - val_accuracy: 0.8072 - val_loss: 1.9361
Epoch 160/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9228 - loss: 0.1930 - val_accuracy: 0.8161 - val_loss: 1.8877
Epoch 161/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9087 - loss: 0.2185 - val_accuracy: 0.8206 - val_loss: 1.8714
Epoch 162/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9219 - loss: 0.2077 - val_accuracy: 0.7982 - val_loss: 1.8634
Epoch 163/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9236 - loss: 0.1848 - val_accuracy: 0.8206 - val_loss: 1.9356
Epoch 164/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9014 - loss: 0.2278 - val_accuracy: 0.8251 - val_loss: 1.9316
Epoch 165/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9297 - loss: 0.1821 - val_accuracy: 0.8117 - val_loss: 2.0098
Epoch 166/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9080 - loss: 0.2141 - val_accuracy: 0.8296 - val_loss: 1.9840
Epoch 167/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9241 - loss: 0.2003 - val_accuracy: 0.8117 - val_loss: 1.9231
Epoch 168/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9093 - loss: 0.2033 - val_accuracy: 0.8161 - val_loss: 1.9485
Epoch 169/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9049 - loss: 0.2183 - val_accuracy: 0.8251 - val_loss: 1.9557
Epoch 170/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9057 - loss: 0.2173 - val_accuracy: 0.8117 - val_loss: 1.9372
Epoch 171/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9197 - loss: 0.1989 - val_accuracy: 0.8206 - val_loss: 1.9695
Epoch 172/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9055 - loss: 0.2403 - val_accuracy: 0.8117 - val_loss: 1.9416
Epoch 173/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9126 - loss: 0.2024 - val_accuracy: 0.8161 - val_loss: 2.0270
Epoch 174/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9190 - loss: 0.2114 - val_accuracy: 0.8117 - val_loss: 2.0630
Epoch 175/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9069 - loss: 0.2111 - val_accuracy: 0.8206 - val_loss: 2.1022
Epoch 176/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9156 - loss: 0.2135 - val_accuracy: 0.7982 - val_loss: 2.1598
Epoch 177/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9094 - loss: 0.2158 - val_accuracy: 0.8206 - val_loss: 2.1567
Epoch 178/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9122 - loss: 0.2049 - val_accuracy: 0.8072 - val_loss: 2.1527
Epoch 179/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8964 - loss: 0.2311 - val_accuracy: 0.8072 - val_loss: 2.1787
Epoch 180/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9075 - loss: 0.2177 - val_accuracy: 0.8027 - val_loss: 2.2352
Epoch 181/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9073 - loss: 0.2131 - val_accuracy: 0.8117 - val_loss: 1.9330
Epoch 182/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8977 - loss: 0.2284 - val_accuracy: 0.8117 - val_loss: 1.9407
Epoch 183/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9147 - loss: 0.2004 - val_accuracy: 0.8296 - val_loss: 1.9101
Epoch 184/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9151 - loss: 0.2007 - val_accuracy: 0.8117 - val_loss: 2.0112
Epoch 185/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9225 - loss: 0.1961 - val_accuracy: 0.8206 - val_loss: 2.0660
Epoch 186/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9253 - loss: 0.1922 - val_accuracy: 0.8117 - val_loss: 2.1485
Epoch 187/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9210 - loss: 0.2142 - val_accuracy: 0.8206 - val_loss: 2.1587
Epoch 188/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9134 - loss: 0.2054 - val_accuracy: 0.8161 - val_loss: 1.9631
Epoch 189/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9137 - loss: 0.2075 - val_accuracy: 0.7982 - val_loss: 2.1524
Epoch 190/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9022 - loss: 0.2224 - val_accuracy: 0.8027 - val_loss: 2.2020
Epoch 191/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9206 - loss: 0.2107 - val_accuracy: 0.8117 - val_loss: 2.2168
Epoch 192/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9074 - loss: 0.2091 - val_accuracy: 0.8117 - val_loss: 2.2054
Epoch 193/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9178 - loss: 0.2138 - val_accuracy: 0.8251 - val_loss: 2.1201
Epoch 194/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9078 - loss: 0.2185 - val_accuracy: 0.8206 - val_loss: 2.1451
Epoch 195/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9156 - loss: 0.1962 - val_accuracy: 0.8206 - val_loss: 2.1810
Epoch 196/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9142 - loss: 0.1864 - val_accuracy: 0.8072 - val_loss: 2.1932
Epoch 197/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9102 - loss: 0.2077 - val_accuracy: 0.8206 - val_loss: 2.1306
Epoch 198/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9122 - loss: 0.2230 - val_accuracy: 0.8027 - val_loss: 2.2611
Epoch 199/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9082 - loss: 0.2241 - val_accuracy: 0.8027 - val_loss: 2.1842
Epoch 200/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.8993 - loss: 0.2270 - val_accuracy: 0.7982 - val_loss: 2.2389
Epoch 201/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9177 - loss: 0.1908 - val_accuracy: 0.8161 - val_loss: 2.2516
Epoch 202/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9275 - loss: 0.1922 - val_accuracy: 0.7982 - val_loss: 2.3478
Epoch 203/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9113 - loss: 0.2057 - val_accuracy: 0.8251 - val_loss: 2.3609
Epoch 204/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9170 - loss: 0.1957 - val_accuracy: 0.7982 - val_loss: 2.2785
Epoch 205/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9049 - loss: 0.2291 - val_accuracy: 0.8251 - val_loss: 2.1180
Epoch 206/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9051 - loss: 0.2010 - val_accuracy: 0.8161 - val_loss: 2.1736
Epoch 207/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9332 - loss: 0.1805 - val_accuracy: 0.8206 - val_loss: 2.0803
Epoch 208/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9142 - loss: 0.2080 - val_accuracy: 0.8072 - val_loss: 2.1005
Epoch 209/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9203 - loss: 0.2045 - val_accuracy: 0.7892 - val_loss: 2.3324
Epoch 210/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9069 - loss: 0.2234 - val_accuracy: 0.7848 - val_loss: 2.7736
Epoch 211/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9192 - loss: 0.2368 - val_accuracy: 0.8027 - val_loss: 1.5454
Epoch 212/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8978 - loss: 0.2573 - val_accuracy: 0.7803 - val_loss: 1.1517
Epoch 213/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9071 - loss: 0.2551 - val_accuracy: 0.7758 - val_loss: 1.0374
Epoch 214/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9016 - loss: 0.2485 - val_accuracy: 0.8072 - val_loss: 0.9112
Epoch 215/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9007 - loss: 0.2578 - val_accuracy: 0.7982 - val_loss: 1.1066
Epoch 216/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9042 - loss: 0.2257 - val_accuracy: 0.8072 - val_loss: 1.1030
Epoch 217/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9149 - loss: 0.2167 - val_accuracy: 0.7848 - val_loss: 1.2617
Epoch 218/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9233 - loss: 0.2147 - val_accuracy: 0.8251 - val_loss: 1.1500
Epoch 219/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9081 - loss: 0.2371 - val_accuracy: 0.7937 - val_loss: 1.2920
Epoch 220/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9214 - loss: 0.2137 - val_accuracy: 0.7982 - val_loss: 1.2232
Epoch 221/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9008 - loss: 0.2419 - val_accuracy: 0.8161 - val_loss: 1.1188
Epoch 222/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9204 - loss: 0.2116 - val_accuracy: 0.8072 - val_loss: 1.2259
Epoch 223/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8947 - loss: 0.2215 - val_accuracy: 0.7982 - val_loss: 1.3546
Epoch 224/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9186 - loss: 0.1976 - val_accuracy: 0.8117 - val_loss: 1.3808
Epoch 225/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9148 - loss: 0.2067 - val_accuracy: 0.8206 - val_loss: 1.3904
Epoch 226/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9233 - loss: 0.1872 - val_accuracy: 0.8161 - val_loss: 1.4109
Epoch 227/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.8977 - loss: 0.2221 - val_accuracy: 0.8072 - val_loss: 1.4569
Epoch 228/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9299 - loss: 0.1682 - val_accuracy: 0.7937 - val_loss: 1.4599
Epoch 229/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9222 - loss: 0.1951 - val_accuracy: 0.8161 - val_loss: 1.4171
Epoch 230/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9279 - loss: 0.1891 - val_accuracy: 0.8206 - val_loss: 1.4438
Epoch 231/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9115 - loss: 0.1979 - val_accuracy: 0.8117 - val_loss: 1.4886
Epoch 232/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9193 - loss: 0.1959 - val_accuracy: 0.7982 - val_loss: 1.5116
Epoch 233/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9065 - loss: 0.2083 - val_accuracy: 0.8072 - val_loss: 1.5837
Epoch 234/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9154 - loss: 0.1979 - val_accuracy: 0.7937 - val_loss: 1.6042
Epoch 235/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9243 - loss: 0.1860 - val_accuracy: 0.7982 - val_loss: 1.6524
Epoch 236/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9287 - loss: 0.1729 - val_accuracy: 0.7982 - val_loss: 1.6007
Epoch 237/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9362 - loss: 0.1780 - val_accuracy: 0.8072 - val_loss: 1.5806
Epoch 238/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9251 - loss: 0.1722 - val_accuracy: 0.7892 - val_loss: 1.6355
Epoch 239/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9195 - loss: 0.1850 - val_accuracy: 0.8161 - val_loss: 1.6360
Epoch 240/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9123 - loss: 0.1994 - val_accuracy: 0.7937 - val_loss: 1.6234
Epoch 241/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9266 - loss: 0.1822 - val_accuracy: 0.8072 - val_loss: 1.6250
Epoch 242/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9271 - loss: 0.1808 - val_accuracy: 0.7937 - val_loss: 1.6264
Epoch 243/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9291 - loss: 0.1882 - val_accuracy: 0.7982 - val_loss: 1.6230
Epoch 244/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9061 - loss: 0.2033 - val_accuracy: 0.8161 - val_loss: 1.6164
Epoch 245/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9224 - loss: 0.1934 - val_accuracy: 0.8027 - val_loss: 1.6767
Epoch 246/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9153 - loss: 0.1981 - val_accuracy: 0.7937 - val_loss: 1.7148
Epoch 247/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9193 - loss: 0.2082 - val_accuracy: 0.8161 - val_loss: 1.6781
Epoch 248/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9271 - loss: 0.1777 - val_accuracy: 0.8117 - val_loss: 1.7112
Epoch 249/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9212 - loss: 0.1772 - val_accuracy: 0.8161 - val_loss: 1.7084
Epoch 250/250
11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.9130 - loss: 0.2118 - val_accuracy: 0.8072 - val_loss: 1.6142Let’s calculate and print the final accuracy scores for both the training and test (validation) data. Remember, we’ll call the function we wrote to do this earlier. You should see training accuracy is much better than test accuracy. We’ve overfitted. Don’t worry - we’ll try and improve that in a moment.
# Show acuracy
calculate_accuracy(model, X_train_sc, X_test_sc, y_train, y_test)21/21 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step
Training accuracy 0.918
Test accuracy 0.80712.4.1 Get training history
history is a dictionary containing data collected during training. Remember - we stored it when we called the model.fit() method. Let’s take a look at the keys in this dictionary (these are the metrics monitored during training).
history_dict = history.history
history_dict.keys()dict_keys(['accuracy', 'loss', 'val_accuracy', 'val_loss'])We see from the above that we have four keys in our history dictionary - loss, accuracy, validation loss and validation accuracy.
12.4.2 Plot training history
Now let’s plot our history data using the plotting function we wrote earlier.
plot_training(history.history)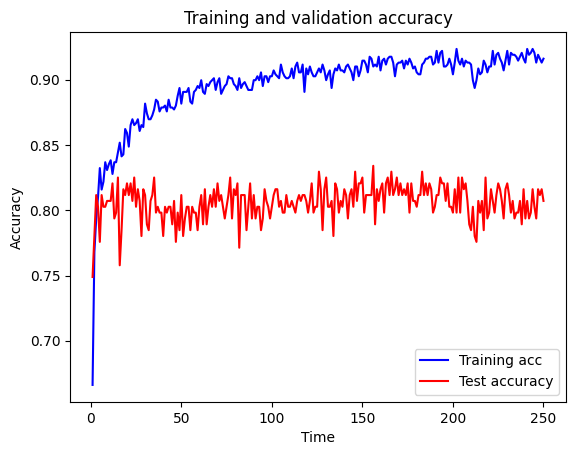
You should see from the plot above that the training accuracy gets better and better before reaching a plateau, but for the test data the accuracy initially improves, but then reduces a bit and plateaus at poorer performance. As we thought, we’ve overfitted. So let’s look at how we can now try to reduce the overfitting.
12.5 Improving fit by avoiding or reducing-over fitting
In the lecture, we discussed a number of strategies we can take to try to reduce overfitting. Let’s look at each in turn.
12.5.1 1) Reduce complexity of model
A simple initial strategy is to reduce the complexity of the model, so that the “dividing line” it learns becomes less complex (and less likely to be an overfit).
Here, we create a new model where we reduce the number of hidden layers to 1 (from the default we used of 3), and we reduce the number of neurons on each hidden layer to 32 (from the default we used of 128).
Then we fit (train) this new model, exactly as we did before. We’ll set verbose to 0 though, so we don’t see everything as it trains (if you’d rather see it, just change verbose to 1 below).
# Define network
number_features = X_train_sc.shape[1]
model = make_net(number_features,
hidden_layers=1,
hidden_layer_neurones=32)
### Train model (and stote training info in history)
history = model.fit(X_train_sc,
y_train,
epochs=250,
batch_size=64,
validation_data=(X_test_sc, y_test),
verbose=0)Let’s calculate, print and plot accuracy as we did before.
# Show acuracy
calculate_accuracy(model, X_train_sc, X_test_sc, y_train, y_test)21/21 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
Training accuracy 0.880
Test accuracy 0.825plot_training(history.history)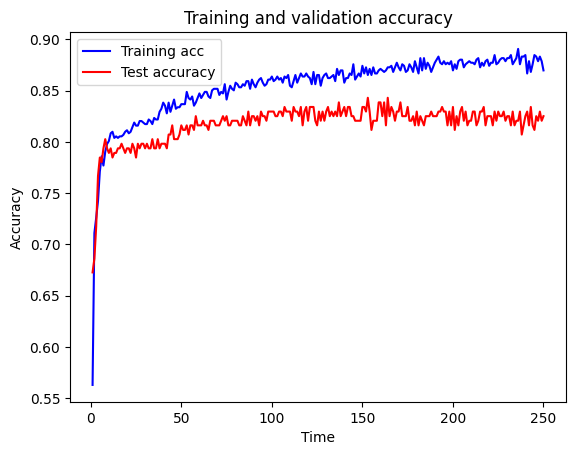
You should see that the simplification of the model above has improved things a bit (though it may not, there’s randomness at play here, and your network may have learned differently) - training accuracy has reduced, but test accuracy (our measure of how generally useful our model will be beyond the training set) has improved - a little bit. But there’s still a bit of a gap between them - we’re still overfitting.
12.5.2 2) Reduce training time
For the moment, let’s do one change at a time, so we’ll go back to our original model before trying our next strategy.
Another approach we can use is simply to stop training for so long. We can see from our earlier plots that things improve in the test set initially but then reduces. So, by not training for so long, we can stop training before it significantly overfits.
Here, we’ll run the model exactly as we did the first time, except we’ll only run it for 25 epochs, rather than 250 - just 10% of the original training time.
# Define network
number_features = X_train_sc.shape[1]
model = make_net(number_features)
### Train model (and stote training info in history)
history = model.fit(X_train_sc,
y_train,
epochs=25,
batch_size=64,
validation_data=(X_test_sc, y_test),
verbose=0)# Show acuracy
calculate_accuracy(model, X_train_sc, X_test_sc, y_train, y_test)21/21 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 834us/step
Training accuracy 0.868
Test accuracy 0.798plot_training(history.history)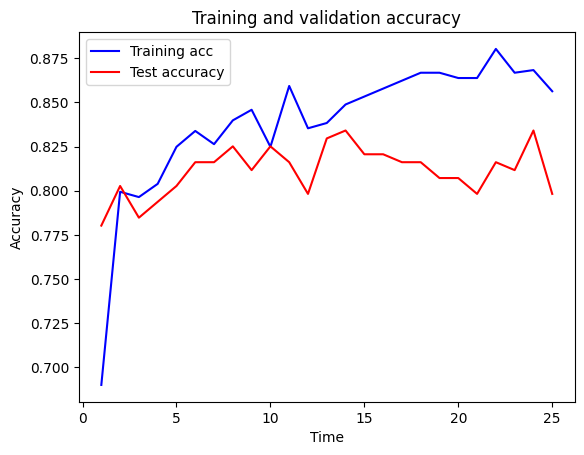
You should see that reducing the training time has also led to an improvement in test accuracy, much as simplifying the model did, although you might not. You might find that this measure is slightly more effective than the simplifying measure. You should also see from the plot that the test set accuracy tends to plateau, and it doesn’t get to the bit where it starts dropping significantly.
12.5.3 3) Add dropout
Using dropout, in each training epoch a random selection of weights are “switched off” (the selection changes from epoch to epoch). It does this by using the Dropout layers after each hidden layer (remember when we added those earlier?), and randomly switching some of the incoming weights to 0. When predicting (after fitting) all weights are used. Dropout ensures that, during training, the model can’t rely too much on any set of weights (because they’ll occasionally be turned off), and looks to explore them more globally.
This is probably the most common method for reducing overfitting. Dropout values of 0.2 to 0.5 are common.
Here, we’ll use a dropout value of 0.5. So 50% of the weights coming out of each hidden layer will be set to 0 in each epoch.
# Define network
number_features = X_train_sc.shape[1]
model = make_net(number_features,
dropout=0.5)
### Train model (and stote training info in history)
history = model.fit(X_train_sc,
y_train,
epochs=250,
batch_size=64,
validation_data=(X_test_sc, y_test),
verbose=0)# Show acuracy
calculate_accuracy(model, X_train_sc, X_test_sc, y_train, y_test)21/21 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step
Training accuracy 0.883
Test accuracy 0.803plot_training(history.history)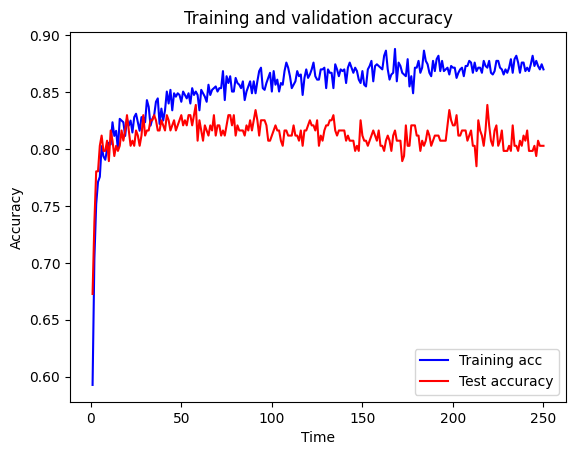
Again, we should see that Dropout has improved performance on the test set over the base case (although it might not).
12.5.4 4) Combination of the above and with automatic early stopping
Rather than just doing one of these things above, we tend to combine these measures. We’ll also use a Keras callback called EarlyStopping to automate the measure where we try to stop the training sooner. A callback is simply a function that Keras can use to perform various actions continually throughout the training.
EarlyStopping will automatically stop the training when it appears the validation accuracy isn’t getting any better. It allows us to specify a patience level, which is the number of epochs we are prepared to wait (to give it a chance to improve) before EarlyStopping cuts things off. We can also optionally specify the minimum level we want our metric(s) (e.g. accuracy) to improve between epochs to count as an “improvement” - this allows us to say that we don’t consider a very small improvement as significant enough. You’ll see examples of this later in the course, but here we’ll just specify patience, and we’ll allow any improvement to count as improvement.
Here, we specify a patience of 25 epochs - this means that we are prepared to wait 25 epochs to see if we can get a better accuracy score on the validation set. By setting restore_best_weights=True we tell it that, once it stops (if it didn’t manage to improve things in 25 epochs), then it should roll back the network to how it was when it reached its peak performance.
So, here we set up our EarlyStopping callback. Then we define a simpler network with 1 hidden layer and 64 neurons per layer, have a 50% dropout rate, and run for 250 epochs but add in the EarlyStopping callback so that Keras will stop the training when things stop improving in the validation set, and revert back to the best version it’s seen.
In the below, you’ll see we’ve also added another callback called ModelCheckpoint. This callback just automatically saves the model at its best point so we can easily retrieve it. In combination with EarlyStopping, this means we have a model that won’t keep going beyond when it should, and it’ll save the best version for later use.
Note that as well as creating and defining the callbacks, you also need to ensure you add them into the list of inputs you pass in when you call model.fit.
# Define save checkpoint callback (only save if new best validation results)
checkpoint_cb = keras.callbacks.ModelCheckpoint(
'model_checkpoint.keras', save_best_only=True)
# Define early stopping callback
# Stop when no validation improvement for 25 epochs
# Restore weights to best validation accuracy
early_stopping_cb = keras.callbacks.EarlyStopping(
patience=25, restore_best_weights=True)
# Define network
number_features = X_train_sc.shape[1]
model = make_net(
number_features,
hidden_layers=1,
hidden_layer_neurones=64,
dropout=0.5)
### Train model (and stote training info in history)
history = model.fit(X_train_sc,
y_train,
epochs=250,
batch_size=64,
validation_data=(X_test_sc, y_test),
verbose=0,
callbacks=[checkpoint_cb, early_stopping_cb])# Show accuracy
calculate_accuracy(model, X_train_sc, X_test_sc, y_train, y_test)21/21 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step
Training accuracy 0.832
Test accuracy 0.812plot_training(history.history)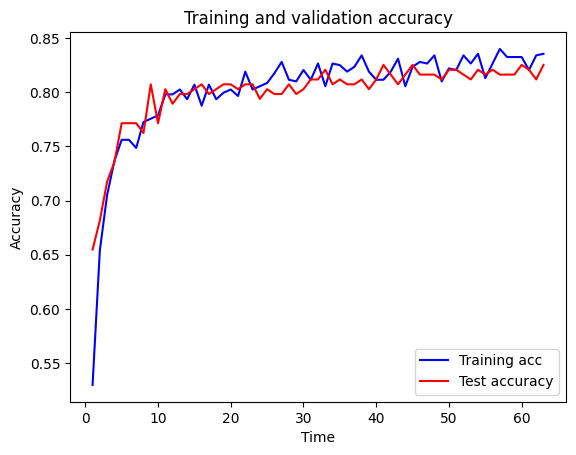
You should see from the above, where we’ve combined the three anti-overfitting measures, that we get quite a decent improvement in test accuracy and a closing of the gap between training and test accuracy. This indicates that our model is far less overfitted than it was originally.
12.6 Saving and reloading the model
Finally, we’ll look at how we can save our models so we can come back to them another time, and we don’t have to retrain them each time. For a small model like this, it’s not hugely inconvenient, but if we had a large model (that could take hours or even days to run) we don’t want to have to retrain it every time we want to use it!
Here, we can use the save() function of the model to easily save a model. We just pass in a filename - we use the new .keras file extension. The model will be saved in the present working directory for the code.
You can also see in the cell below how to load a model back in, and then use it again. You can verify this if you run the two cells below, which will save the model, then load it back up, and recalculate its accuracy - you should see that the reported training and test accuracies are the same as you had above (because that’s the model we saved and then loaded back up).
# Save model
model.save('titanic_tf_model.keras')
# Load and use saved model - we need to first set up a model
restored_model = keras.models.load_model('titanic_tf_model.keras')
# Predict classes as normal
predicted_proba = restored_model.predict(X_test_sc)
# Show examples of predicted probability
print(predicted_proba[0:5].flatten())7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step
[0.09658381 0.15201195 0.15485787 0.85435104 0.68767977]calculate_accuracy(restored_model, X_train_sc, X_test_sc, y_train, y_test)21/21 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step
Training accuracy 0.832
Test accuracy 0.812