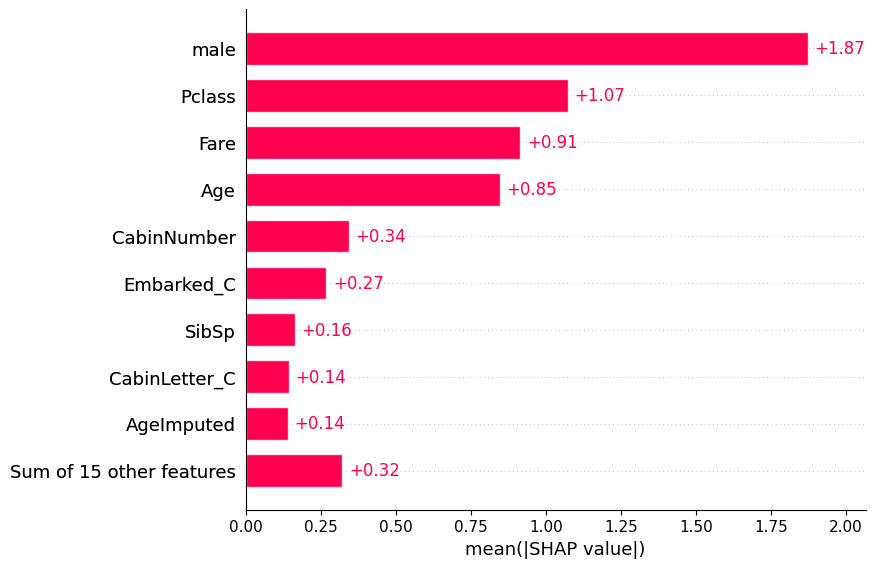
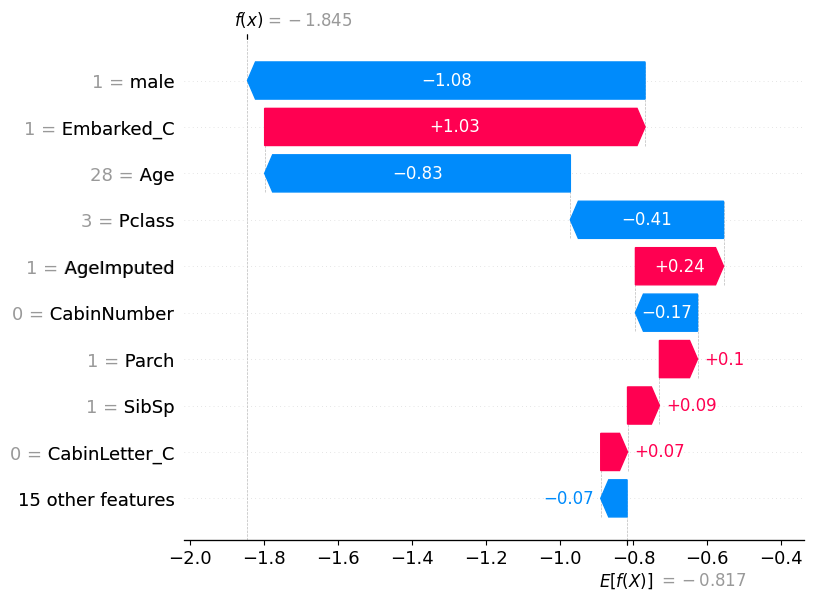
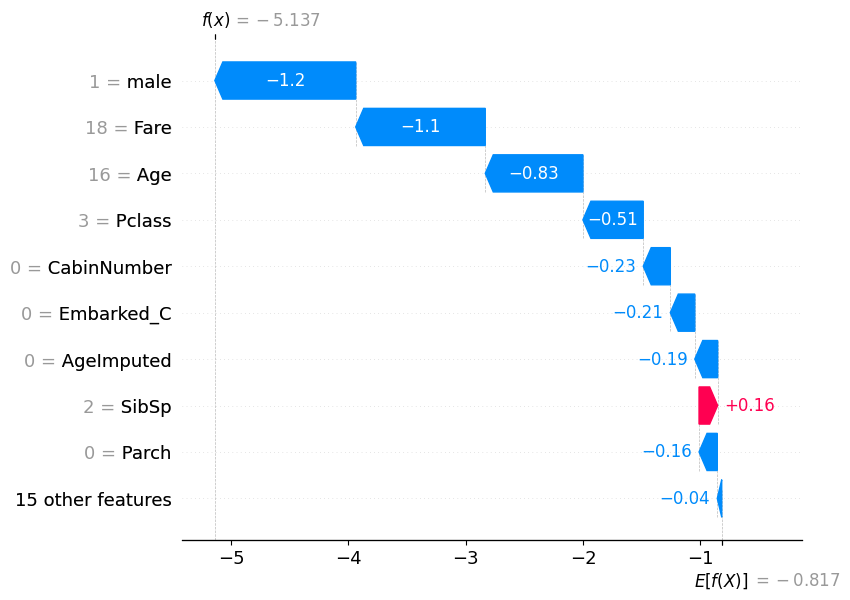
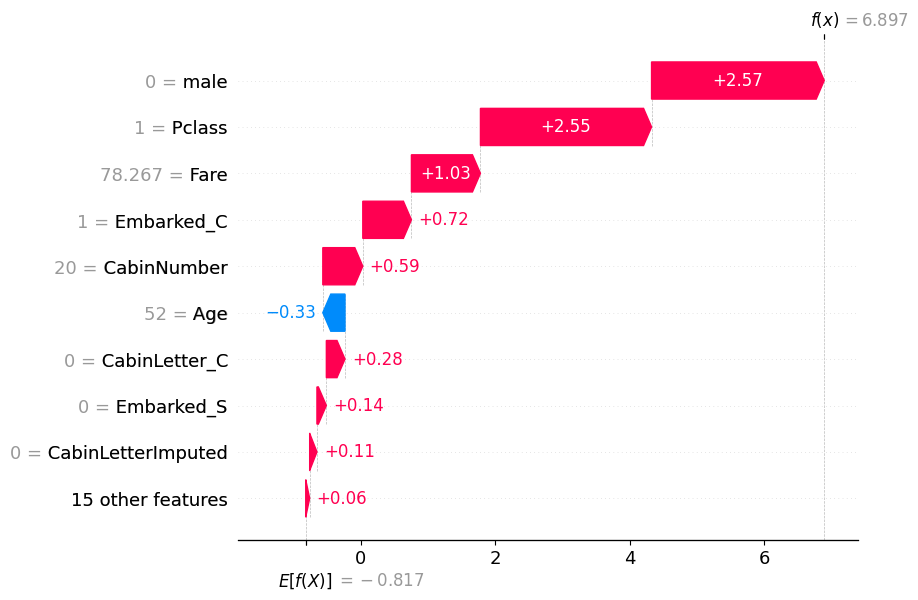
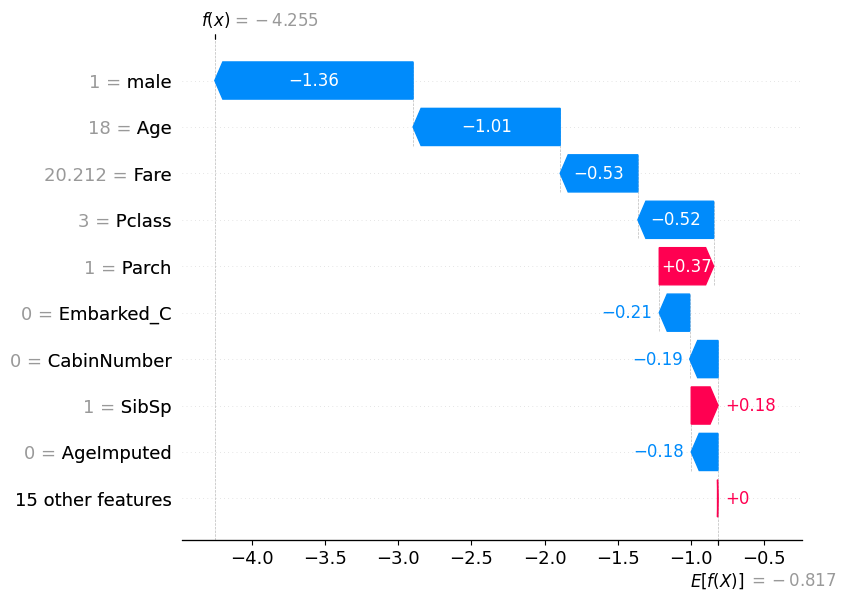
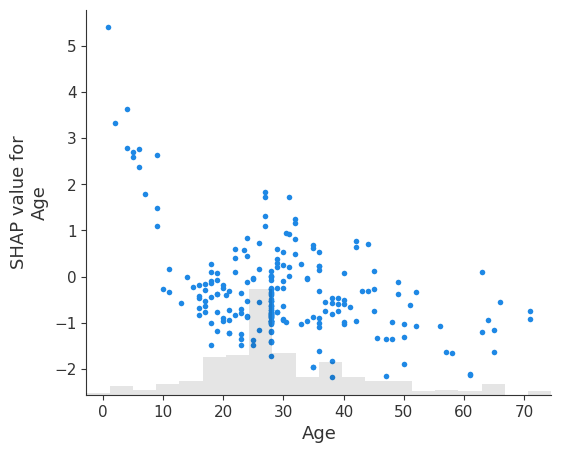
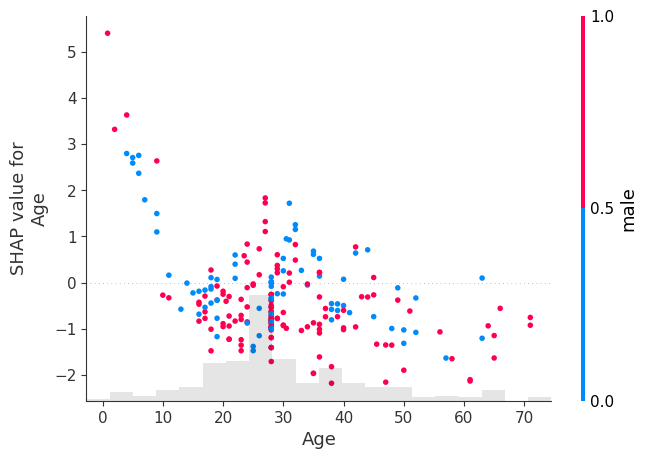
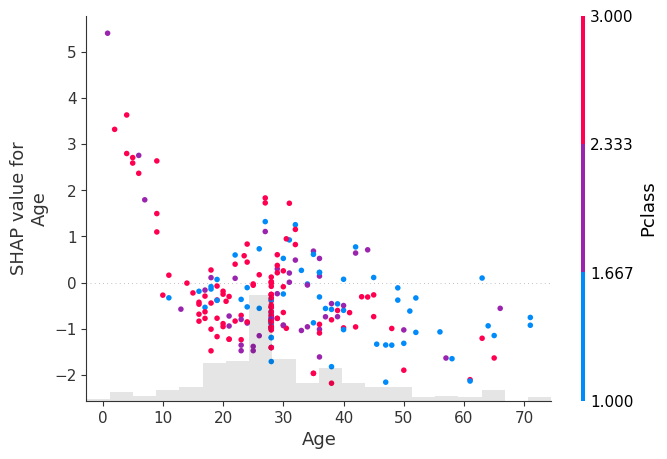
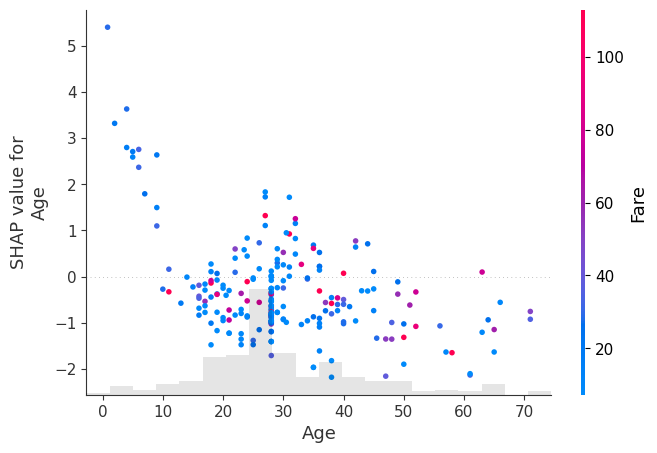
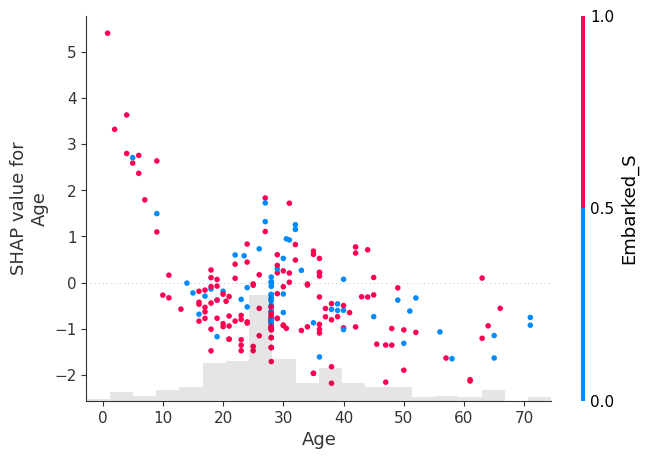
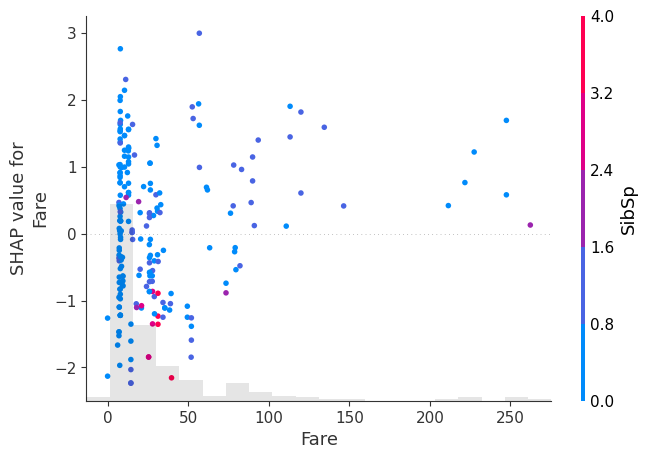
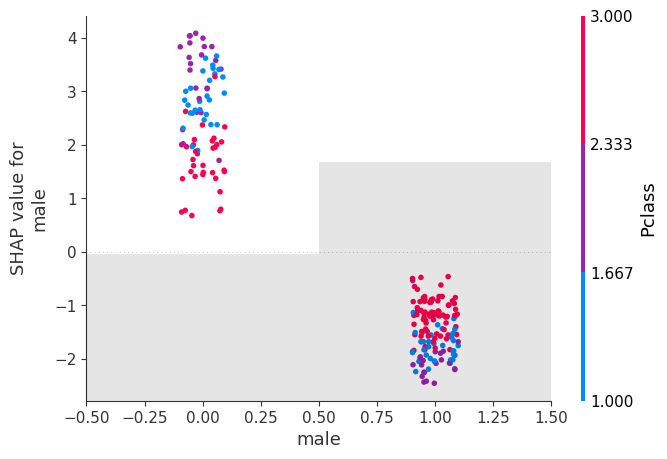
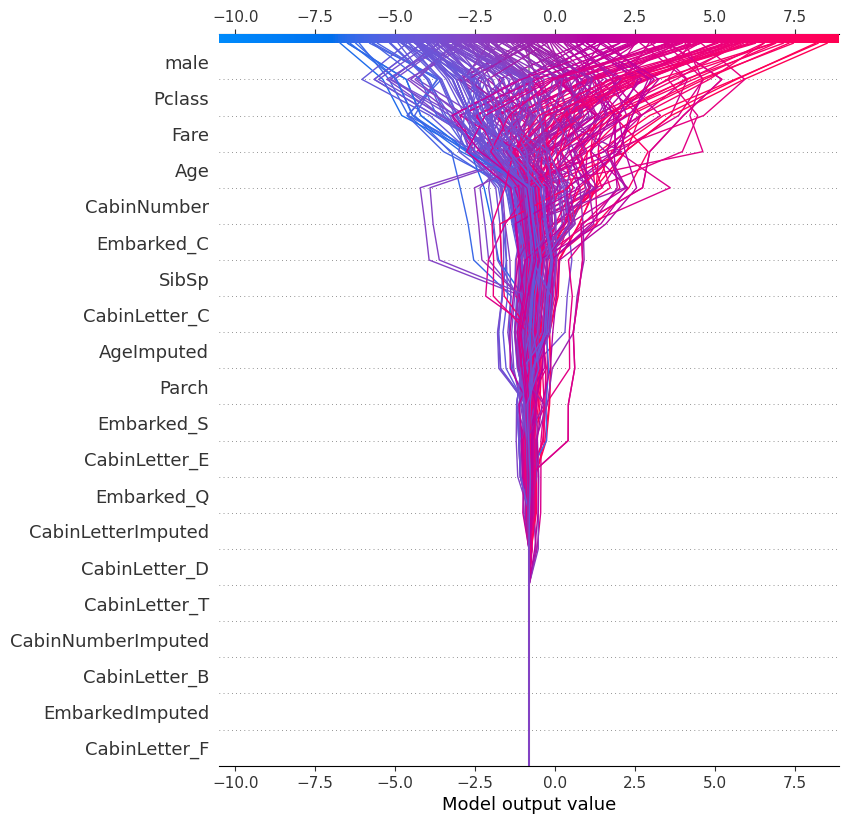
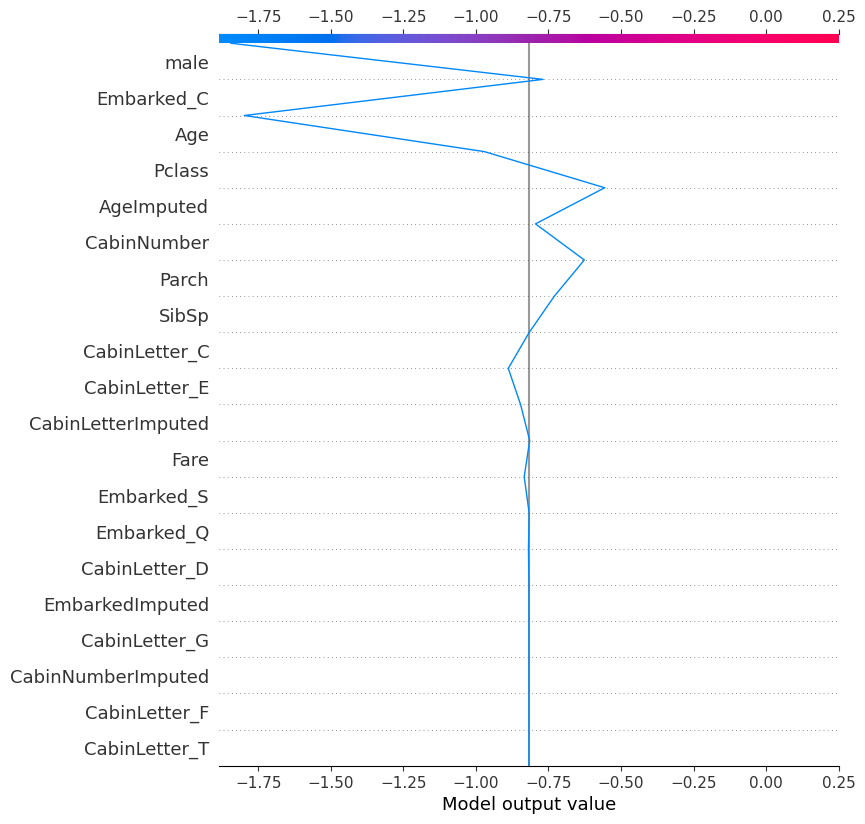
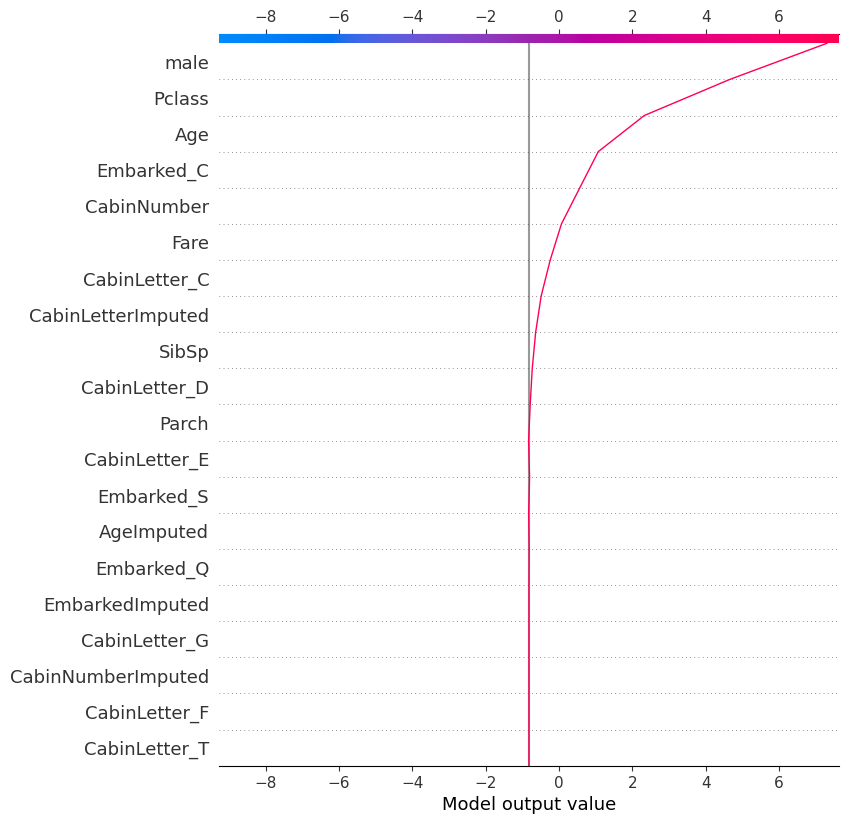
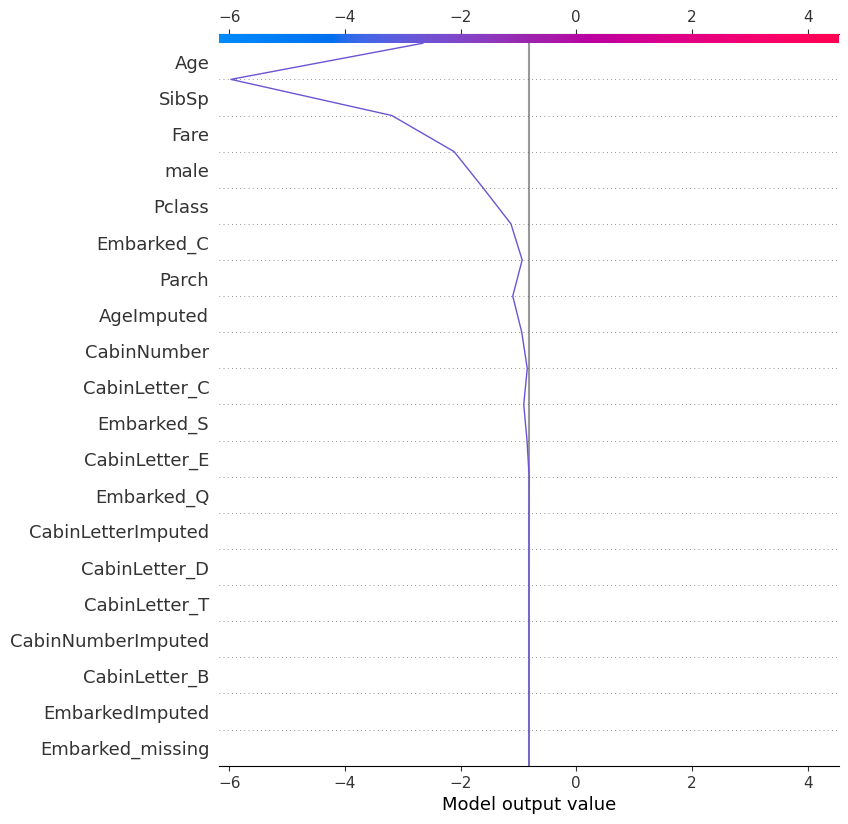
.values =
array([[-0.41472028, -0.82758431, 0.08631781, ..., 0. ,
0. , 0. ],
[ 0.34368675, 0.01027041, 0.20749824, ..., 0. ,
0. , 0. ],
[-0.49629094, -0.24858944, -0.07239207, ..., 0. ,
0. , 0. ],
...,
[-0.45505765, -0.95988004, 0.14636154, ..., 0. ,
0. , 0. ],
[ 1.38846514, -0.87314281, 0.06420199, ..., 0. ,
0. , 0. ],
[-0.51810456, -1.0059387 , 0.18350499, ..., 0. ,
0. , 0. ]])
.base_values =
array([-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838, -0.81725838, -0.81725838,
-0.81725838, -0.81725838, -0.81725838])
.data =
array([[ 3., 28., 1., ..., 0., 0., 1.],
[ 2., 31., 0., ..., 0., 0., 1.],
[ 3., 20., 0., ..., 0., 0., 1.],
...,
[ 3., 28., 0., ..., 0., 0., 1.],
[ 2., 24., 0., ..., 0., 0., 1.],
[ 3., 18., 1., ..., 0., 0., 1.]])