# Class to store global parameter values. We don't create an instance of this
# class - we just refer to the class blueprint itself to access the numbers
# inside.
class g:
patient_inter = 5
mean_reception_time = 2
mean_n_consult_time = 6
mean_d_consult_time = 20
number_of_receptionists = 1
number_of_nurses = 2
number_of_doctors = 2
number_of_cubicles = 5 ##NEW
prob_seeing_doctor = 0.6
sim_duration = 1800
number_of_runs = 1021 Requesting Multiple Resources Simultaneously
In your models, you may sometimes require multiple kinds of resources to be available for a single step.
For example, in an emergency department, you may need both a cubicle and a nurse to be available so a patient can be seen. Cubicles may be released slower than nurses if the patient in the cubicle is now waiting for a different step of their journey in the cubicle, such as having an x-ray, seeing a different type of practitioner, or waiting for a bed to become available within the hospital so they can be admitted.
Imagine this department is having problems seeing patients fast enough. They have 15 cubicles, and 8 nurses. They can either increase the number of nurses on shift to 9, or increase the capacity to 18 cubicles. Which should they do?
By setting up a model where we look at how both kinds of resources are used, we can begin to explore these questions.
21.1 Code example
Let’s return to our branching model from before.
Remember, in this, patients - see a receptionist - see a nurse - have a chance of going on to see a doctor
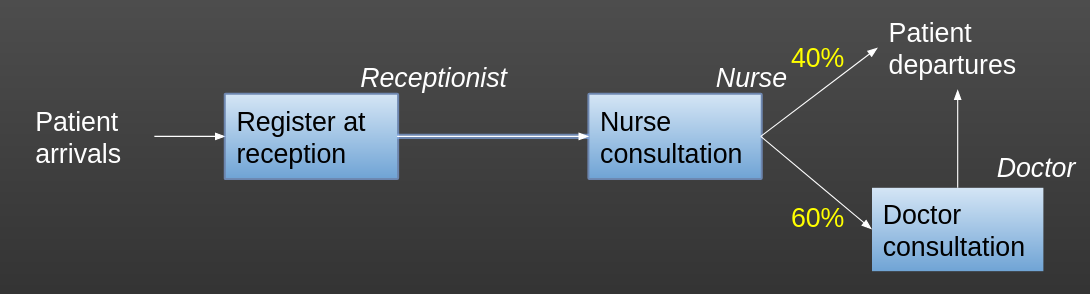
In the original version of the model, we assumed that there was always a room available for patients to be seen in. Maybe each nurse and doctor in this example clinic has their own designated room they are always in.
But let’s imagine the setup is slightly different - patients see a receptionist and go to a waiting area - once both a cubicle and a nurse are available, the patient is seen by a nurse - if the patient then needs to see a doctor (which, as before, only a certain % of patients will) then they will remain in the same cubicle while waiting for a doctor - the doctor will see them in the cubicle
The cubicle is released for the next patient after seeing the nurse IF the patient leaves at this point. Otherwise, it will be released after seeing the doctor.
21.1.1 The g class
We add in an additional parameter for the number of
21.1.2 The Patient class
We add in an new attribute where we will record the time spent queueing for a cubicle.
class Patient:
def __init__(self, p_id):
self.id = p_id
self.q_time_recep = 0
self.q_time_nurse = 0
self.q_time_doctor = 0
self.q_time_cubicle = 0 ##NEW21.1.3 The model class
21.1.3.1 The init method
We do several things here:
- create a new cubicle resource using the number of cubicles we set in g
- create columns in our patient-level results dataframe for cubicle queuing time and time in the cubicle
- add an attribute for storing the average cubicle queueing time
def __init__(self, run_number):
# Create a SimPy environment in which everything will live
self.env = simpy.Environment()
# Create a patient counter (which we'll use as a patient ID)
self.patient_counter = 0
# Create our resources
self.receptionist = simpy.Resource(self.env, capacity=g.number_of_receptionists)
self.nurse = simpy.Resource(self.env, capacity=g.number_of_nurses)
self.doctor = simpy.Resource(self.env, capacity=g.number_of_doctors)
self.cubicle = simpy.Resource(self.env, capacity=g.number_of_cubicles) ## NEW
# Store the passed in run number
self.run_number = run_number
# Create a new Pandas DataFrame that will store some results against
# the patient ID (which we'll use as the index).
self.results_df = pd.DataFrame()
self.results_df["Patient ID"] = [1]
self.results_df["Q Time Recep"] = [0.0]
self.results_df["Time with Recep"] = [0.0]
self.results_df["Q Time Nurse"] = [0.0]
self.results_df["Time with Nurse"] = [0.0]
self.results_df["Q Time Doctor"] = [0.0]
self.results_df["Time with Doctor"] = [0.0]
self.results_df["Q Time Cubicle"] = [0.0] ##NEW
self.results_df["Time Using Cubicle"] = [0.0] ##NEW
self.results_df.set_index("Patient ID", inplace=True)
# Create an attribute to store the mean queuing times across this run of
# the model
self.mean_q_time_recep = 0
self.mean_q_time_nurse = 0
self.mean_q_time_doctor = 0
self.mean_q_time_cubicle = 0 ##NEW21.1.4 The generator_patient_arrivals method
This method is unchanged.
21.1.5 The attend_clinic method
This is where the majority of our changes take place.
Tip
There are two ways you can request a resource in simpy.
We’ve used the first method so far:
with self.receptionist.request() as req:
yield req
## the rest of the code you want to run while holding on
## to this resourceHowever, an alternative option is this:
nurse_request = self.receptionist.request()
yield nurse_request
## the rest of the code you want to run while holding on
## to this resource
self.nurse.release(nurse_request)Here, we don’t use indentation, and instead manually specify when we stop using the nurse and pass it back to the pool of available resources.
It’s useful to know about this second option as it gives us an easier way of writing the code for requesting multiple resources at once.
Once we finish our time with the receptionist, we are going to record two attributes.
# Record the time the patient started queuing for a nurse
start_q_nurse = self.env.now
start_q_cubicle = self.env.now ##NEWYes, they are the same - but it’s a bit easier to refer back to them when they are named separately!
Next we are going to request both a nurse and a cubicle.
nurse_request = self.nurse.request() ##NEW
cubicle_request = self.cubicle.request() ##NEWWe then place both of these requests in a list, and wait until either of them become available.
clinic_resource = yield self.env.any_of([nurse_request,cubicle_request]) ##NEWNext, we have to check three possible scenarios and act accordingly: - both were available at the same time - we got the nurse but are still waiting for a cubicle - we got the cubicle but are still waiting for a nurse
clinic_resource_list = list(clinic_resource.keys()) ##NEW
if len(clinic_resource_list) < 2:
## Work out which we didn't get and wait for that one
got_resource = clinic_resource_list[0]
if got_resource == nurse_request:
end_q_nurse = self.env.now
yield(cubicle_request)
end_q_cubicle = self.env.now
else:
end_q_cubicle = self.env.now
yield(nurse_request)
end_q_nurse = self.env.now
else:
end_q_cubicle = self.env.now
end_q_nurse = self.env.now
patient.q_time_cubicle = end_q_cubicle - start_q_cubicle
self.results_df.at[patient.id, "Q Time Cubicle"] = (
patient.q_time_cubicle
)
# Calculate the time this patient was queuing for the nurse, and
# record it in the patient's attribute for this.
patient.q_time_nurse = end_q_nurse - start_q_nurse
self.results_df.at[patient.id, "Q Time Nurse"] = (
patient.q_time_nurse
)
Tip
Remember - we don’t have to indent all of the code where the resource is used here because we will manually specify when we release it.
You can still use the first method of requesting resources on top of this one - for example, our code for requesting a doctor is unchanged.
We just don’t release the cubicle resource until that section completes.
Now, the only thing left to do is to find the right place to release both resources.
For the nurse, this is after the activity time has elapsed.
## Other code relating to nurse activity...
# Freeze this function in place for the activity time we sampled
# above. This is the patient spending time with the nurse.
yield self.env.timeout(sampled_nurse_act_time)
# When the time above elapses, the generator function will return
# here. As there's nothing moref that we've written, the function
# will simply end. This is a sink. We could choose to add
# something here if we wanted to record something - e.g. a counter
# for number of patients that left, recording something about the
# patients that left at a particular sink etc.
self.nurse.release(nurse_request) ##NEWFinally, for the cubicle, we don’t release this until either after sampling to decide whether the patient goes on to see a doctor, and release it accordingly.
Previously we just had an if clause with no else for seeing the doctor. However, now we need to release the cubicle and record the total time spent in the cubicle even if they don’t see a doctor, so the else clause becomes necessary.
if random.uniform(0,1) < g.prob_seeing_doctor:
start_q_doctor = self.env.now
with self.doctor.request() as req:
yield req
end_q_doctor = self.env.now
patient.q_time_doctor = end_q_doctor - start_q_doctor
sampled_doctor_act_time = random.expovariate(
1.0 / g.mean_d_consult_time
)
self.results_df.at[patient.id, "Q Time Doctor"] = (
patient.q_time_doctor
)
self.results_df.at[patient.id, "Time with Doctor"] = (
sampled_doctor_act_time
)
yield self.env.timeout(sampled_doctor_act_time)
self.results_df.at[patient.id, "Time Using Cubicle"] = ( ##NEW
self.env.now - end_q_cubicle
)
self.cubicle.release(cubicle_request) ##NEW
else: ## NEW
self.results_df.at[patient.id, "Time Using Cubicle"] = ( ##NEW
self.env.now - end_q_cubicle
)
self.cubicle.release(cubicle_request) ##NEWThe only step remaining now is to record the average queueing time for a cubicle.
self.mean_q_time_recep = self.results_df["Q Time Recep"].mean()
self.mean_q_time_nurse = self.results_df["Q Time Nurse"].mean()
self.mean_q_time_doctor = self.results_df["Q Time Doctor"].mean()
self.mean_q_time_cubicle = self.results_df["Q Time Cubicle"].mean() ##NEW21.1.6 The trial class
21.1.6.1 The init method
In the init method, we add in a column for the average cubicle queue time per run.
self.df_trial_results = pd.DataFrame()
self.df_trial_results["Run Number"] = [0]
self.df_trial_results["Mean Q Time Recep"] = [0.0]
self.df_trial_results["Mean Q Time Nurse"] = [0.0]
self.df_trial_results["Mean Q Time Doctor"] = [0.0]
self.df_trial_results["Mean Q Time Cubicle"] = [0.0] ##NEW
self.df_trial_results.set_index("Run Number", inplace=True)21.1.6.2 The run method
In the run method, we just need to add the cubcicle queueing mean to the results dataframe after each run.
After all runs are complete, w can also add in a column that checks which was longer on average - the queue for the cubicle, or the queue for the nurse. This can give an indication of which is the limiting resource.
for run in range(g.number_of_runs):
my_model = Model(run)
my_model.run()
self.df_trial_results.loc[run] = [my_model.mean_q_time_recep,
my_model.mean_q_time_nurse,
my_model.mean_q_time_doctor,
my_model.mean_q_time_cubicle ##NEW
]
# Once the trial (ie all runs) has completed, add an additional column
self.df_trial_results['nurse_queue_longer'] = np.where(self.df_trial_results['Mean Q Time Nurse'] > self.df_trial_results['Mean Q Time Cubicle'], True, False) ##NEW
# Print the final results
self.print_trial_results()
print(f"Queue for nurse was longer than queue for cubicle in {sum(self.df_trial_results['nurse_queue_longer'].values)} trials of {g.number_of_runs}")21.2 The Full Code
Click here to view the full code
import simpy
import random
import pandas as pd
import numpy as np ##NEW
# Class to store global parameter values. We don't create an instance of this
# class - we just refer to the class blueprint itself to access the numbers
# inside.
class g:
patient_inter = 5
mean_reception_time = 2
mean_n_consult_time = 6
mean_d_consult_time = 20
number_of_receptionists = 1
number_of_nurses = 2
number_of_doctors = 2
number_of_cubicles = 5 ##NEW
prob_seeing_doctor = 0.6
sim_duration = 600
number_of_runs = 100
# Class representing patients coming in to the clinic.
class Patient:
def __init__(self, p_id):
self.id = p_id
self.q_time_recep = 0
self.q_time_nurse = 0
self.q_time_doctor = 0
self.q_time_cubicle = 0 ##NEW
# Class representing our model of the clinic.
class Model:
# Constructor to set up the model for a run. We pass in a run number when
# we create a new model.
def __init__(self, run_number):
# Create a SimPy environment in which everything will live
self.env = simpy.Environment()
# Create a patient counter (which we'll use as a patient ID)
self.patient_counter = 0
# Create our resources
self.receptionist = simpy.Resource(self.env, capacity=g.number_of_receptionists)
self.nurse = simpy.Resource(self.env, capacity=g.number_of_nurses)
self.doctor = simpy.Resource(self.env, capacity=g.number_of_doctors)
self.cubicle = simpy.Resource(self.env, capacity=g.number_of_cubicles) ## NEW
# Store the passed in run number
self.run_number = run_number
# Create a new Pandas DataFrame that will store some results against
# the patient ID (which we'll use as the index).
self.results_df = pd.DataFrame()
self.results_df["Patient ID"] = [1]
self.results_df["Q Time Recep"] = [0.0]
self.results_df["Time with Recep"] = [0.0]
self.results_df["Q Time Nurse"] = [0.0]
self.results_df["Time with Nurse"] = [0.0]
self.results_df["Q Time Doctor"] = [0.0]
self.results_df["Time with Doctor"] = [0.0]
self.results_df["Q Time Cubicle"] = [0.0] ##NEW
self.results_df["Time Using Cubicle"] = [0.0] ##NEW
self.results_df.set_index("Patient ID", inplace=True)
# Create an attribute to store the mean queuing times across this run of
# the model
self.mean_q_time_recep = 0
self.mean_q_time_nurse = 0
self.mean_q_time_doctor = 0
self.mean_q_time_cubicle = 0 ##NEW
# A generator function that represents the DES generator for patient
# arrivals
def generator_patient_arrivals(self):
# We use an infinite loop here to keep doing this indefinitely whilst
# the simulation runs
while True:
# Increment the patient counter by 1 (this means our first patient
# will have an ID of 1)
self.patient_counter += 1
# Create a new patient - an instance of the Patient Class we
# defined above. Remember, we pass in the ID when creating a
# patient - so here we pass the patient counter to use as the ID.
p = Patient(self.patient_counter)
# Tell SimPy to start up the attend_clinic generator function with
# this patient (the generator function that will model the
# patient's journey through the system)
self.env.process(self.attend_clinic(p))
# Randomly sample the time to the next patient arriving. Here, we
# sample from an exponential distribution (common for inter-arrival
# times), and pass in a lambda value of 1 / mean. The mean
# inter-arrival time is stored in the g class.
sampled_inter = random.expovariate(1.0 / g.patient_inter)
# Freeze this instance of this function in place until the
# inter-arrival time we sampled above has elapsed. Note - time in
# SimPy progresses in "Time Units", which can represent anything
# you like (just make sure you're consistent within the model)
yield self.env.timeout(sampled_inter)
# A generator function that represents the pathway for a patient going
# through the clinic.
# The patient object is passed in to the generator function so we can
# extract information from / record information to it
def attend_clinic(self, patient):
start_q_recep = self.env.now
with self.receptionist.request() as req:
yield req
end_q_recep = self.env.now
patient.q_time_recep = end_q_recep - start_q_recep
sampled_recep_act_time = random.expovariate(
1.0 / g.mean_reception_time
)
self.results_df.at[patient.id, "Q Time Recep"] = (
patient.q_time_recep
)
self.results_df.at[patient.id, "Time with Recep"] = (
sampled_recep_act_time
)
yield self.env.timeout(sampled_recep_act_time)
# Here's where the patient finishes with the receptionist, and starts
# queuing for the nurse
# NEW: They will also be queueing for a cubicle at this point.
#
# Record the time the patient started queuing for a nurse
start_q_nurse = self.env.now
start_q_cubicle = self.env.now ##NEW
########
##NEW
########
# As we are going to require the cubicle for the entire time period from
# here on, and won't release it until they exit the system, we will request
# the cubicle here and indent all of the existing code by one level.
nurse_request = self.nurse.request() ##NEW
cubicle_request = self.cubicle.request() ##NEW
clinic_resource = yield self.env.any_of([nurse_request,cubicle_request]) ##NEW
# First, check if both were available at once. If so, we can continue.
clinic_resource_list = list(clinic_resource.keys()) ##NEW
if len(clinic_resource_list) < 2:
## Work out which we didn't get and wait for that one
got_resource = clinic_resource_list[0]
if got_resource == nurse_request:
#print(f"{patient.id} got nurse first at {self.env.now}")
end_q_nurse = self.env.now
yield(cubicle_request)
end_q_cubicle = self.env.now
#print(f"{patient.id} got cubicle at {self.env.now}")
else:
#print(f"{patient.id} got cubicle first at {self.env.now}")
end_q_cubicle = self.env.now
yield(nurse_request)
end_q_nurse = self.env.now
#print(f"{patient.id} got nurse at {self.env.now}")
else:
#print(f"{patient.id} got both resources simultaneously at {self.env.now}")
end_q_cubicle = self.env.now
end_q_nurse = self.env.now
patient.q_time_cubicle = end_q_cubicle - start_q_cubicle
self.results_df.at[patient.id, "Q Time Cubicle"] = (
patient.q_time_cubicle
)
# Calculate the time this patient was queuing for the nurse, and
# record it in the patient's attribute for this.
patient.q_time_nurse = end_q_nurse - start_q_nurse
self.results_df.at[patient.id, "Q Time Nurse"] = (
patient.q_time_nurse
)
########
##END NEW
########
# Now we'll randomly sample the time this patient with the nurse.
# Here, we use an Exponential distribution for simplicity, but you
# would typically use a Log Normal distribution for a real model
# (we'll come back to that). As with sampling the inter-arrival
# times, we grab the mean from the g class, and pass in 1 / mean
# as the lambda value.
sampled_nurse_act_time = random.expovariate(1.0 /
g.mean_n_consult_time)
# Here we'll store the queuing time for the nurse and the sampled
# time to spend with the nurse in the results DataFrame against the
# ID for this patient. In real world models, you may not want to
# bother storing the sampled activity times - but as this is a
# simple model, we'll do it here.
# We use a handy property of pandas called .at, which works a bit
# like .loc. .at allows us to access (and therefore change) a
# particular cell in our DataFrame by providing the row and column.
# Here, we specify the row as the patient ID (the index), and the
# column for the value we want to update for that patient.
self.results_df.at[patient.id, "Time with Nurse"] = (
sampled_nurse_act_time)
# Freeze this function in place for the activity time we sampled
# above. This is the patient spending time with the nurse.
yield self.env.timeout(sampled_nurse_act_time)
# When the time above elapses, the generator function will return
# here. As there's nothing moref that we've written, the function
# will simply end. This is a sink. We could choose to add
# something here if we wanted to record something - e.g. a counter
# for number of patients that left, recording something about the
# patients that left at a particular sink etc.
self.nurse.release(nurse_request) ##NEW
# Conditional logic to see if patient goes on to see doctor
# We sample from the uniform distribution between 0 and 1. If the value
# is less than the probability of seeing a doctor (stored in g Class)
# then we say the patient sees a doctor.
# If not, this block of code won't be run and the patient will just
# leave the system (we could add in an else if we wanted a branching
# path to another activity instead)
if random.uniform(0,1) < g.prob_seeing_doctor:
start_q_doctor = self.env.now
with self.doctor.request() as req:
yield req
end_q_doctor = self.env.now
patient.q_time_doctor = end_q_doctor - start_q_doctor
sampled_doctor_act_time = random.expovariate(
1.0 / g.mean_d_consult_time
)
self.results_df.at[patient.id, "Q Time Doctor"] = (
patient.q_time_doctor
)
self.results_df.at[patient.id, "Time with Doctor"] = (
sampled_doctor_act_time
)
yield self.env.timeout(sampled_doctor_act_time)
self.results_df.at[patient.id, "Time Using Cubicle"] = ( ##NEW
self.env.now - end_q_cubicle
)
self.cubicle.release(cubicle_request) ##NEW
else: ## NEW
self.results_df.at[patient.id, "Time Using Cubicle"] = ( ##NEW
self.env.now - end_q_cubicle
)
self.cubicle.release(cubicle_request) ##NEW
# This method calculates results over a single run. Here we just calculate
# a mean, but in real world models you'd probably want to calculate more.
def calculate_run_results(self):
# Take the mean of the queuing times across patients in this run of the
# model.
self.mean_q_time_recep = self.results_df["Q Time Recep"].mean()
self.mean_q_time_nurse = self.results_df["Q Time Nurse"].mean()
self.mean_q_time_doctor = self.results_df["Q Time Doctor"].mean()
self.mean_q_time_cubicle = self.results_df["Q Time Cubicle"].mean() ##NEW
# The run method starts up the DES entity generators, runs the simulation,
# and in turns calls anything we need to generate results for the run
def run(self):
# Start up our DES entity generators that create new patients. We've
# only got one in this model, but we'd need to do this for each one if
# we had multiple generators.
self.env.process(self.generator_patient_arrivals())
# Run the model for the duration specified in g class
self.env.run(until=g.sim_duration)
# Now the simulation run has finished, call the method that calculates
# run results
self.calculate_run_results()
# Print the run number with the patient-level results from this run of
# the model
# EDIT: Omit patient-level results in this model
# print (f"Run Number {self.run_number}")
# print (self.results_df)
# Class representing a Trial for our simulation - a batch of simulation runs.
class Trial:
# The constructor sets up a pandas dataframe that will store the key
# results from each run against run number, with run number as the index.
def __init__(self):
self.df_trial_results = pd.DataFrame()
self.df_trial_results["Run Number"] = [0]
self.df_trial_results["Mean Q Time Recep"] = [0.0]
self.df_trial_results["Mean Q Time Nurse"] = [0.0]
self.df_trial_results["Mean Q Time Doctor"] = [0.0]
self.df_trial_results["Mean Q Time Cubicle"] = [0.0] ##NEW
self.df_trial_results.set_index("Run Number", inplace=True)
# Method to print out the results from the trial. In real world models,
# you'd likely save them as well as (or instead of) printing them
def print_trial_results(self):
print ("Trial Results")
print (self.df_trial_results.round(1)) ##EDITED: Added rounding
# Method to run a trial
def run_trial(self):
# Run the simulation for the number of runs specified in g class.
# For each run, we create a new instance of the Model class and call its
# run method, which sets everything else in motion. Once the run has
# completed, we grab out the stored run results (just mean queuing time
# here) and store it against the run number in the trial results
# dataframe.
for run in range(g.number_of_runs):
my_model = Model(run)
my_model.run()
self.df_trial_results.loc[run] = [my_model.mean_q_time_recep,
my_model.mean_q_time_nurse,
my_model.mean_q_time_doctor,
my_model.mean_q_time_cubicle ##NEW
]
# Once the trial (ie all runs) has completed, add an additional column
self.df_trial_results['nurse_queue_longer'] = np.where(self.df_trial_results['Mean Q Time Nurse'] > self.df_trial_results['Mean Q Time Cubicle'], True, False) ##NEW
# Print the final results
self.print_trial_results()
print(f"Queue for nurse was longer than queue for cubicle in {sum(self.df_trial_results['nurse_queue_longer'].values)} trials of {g.number_of_runs}")21.3 Evaluating the outputs
Warning
We haven’t fully controlled the randomness in our trials here, so the different trials will each have slightly differing arrival times and activity times. Even though we have run a high number of trials to compensate, this is not an ideal solution.
For information on how to properly control for randomness across trials, make sure to read the reproducibility section (Chapter 13).
9 cubicles, 2 nurses, 2 doctors
Trial Results
Mean Q Time Recep Mean Q Time Nurse Mean Q Time Doctor \
Run Number
0 0.6 3.3 30.4
1 0.8 51.3 36.0
2 1.6 3.9 24.5
3 2.0 27.8 34.2
4 1.0 4.2 16.0
... ... ... ...
95 1.2 28.5 37.4
96 1.3 52.0 48.8
97 0.8 24.3 41.8
98 1.1 32.2 42.6
99 1.4 29.1 46.9
Mean Q Time Cubicle nurse_queue_longer
Run Number
0 4.4 False
1 51.2 True
2 2.4 True
3 28.6 False
4 0.5 True
... ... ...
95 30.5 False
96 54.9 False
97 27.0 False
98 34.3 False
99 33.0 False
[100 rows x 5 columns]
Queue for nurse was longer than queue for cubicle in 27 trials of 1003 cubicles, 2 nurses, 2 doctors
Trial Results
Mean Q Time Recep Mean Q Time Nurse Mean Q Time Doctor \
Run Number
0 1.0 100.0 4.1
1 0.8 118.5 4.8
2 1.6 107.1 4.7
3 1.4 66.2 4.3
4 0.8 46.5 2.5
... ... ... ...
95 0.7 74.5 3.4
96 1.5 55.4 3.3
97 0.7 66.6 4.3
98 1.1 53.6 3.5
99 0.7 28.5 3.5
Mean Q Time Cubicle nurse_queue_longer
Run Number
0 107.2 False
1 127.3 False
2 115.2 False
3 73.3 False
4 51.9 False
... ... ...
95 80.9 False
96 61.3 False
97 73.7 False
98 60.0 False
99 34.5 False
[100 rows x 5 columns]
Queue for nurse was longer than queue for cubicle in 0 trials of 10012 cubicles, 2 nurses, 2 doctors
Trial Results
Mean Q Time Recep Mean Q Time Nurse Mean Q Time Doctor \
Run Number
0 1.1 1.6 36.6
1 0.6 3.5 47.7
2 1.1 2.5 11.2
3 1.5 8.3 32.9
4 2.2 29.8 81.2
... ... ... ...
95 2.1 50.9 63.8
96 0.9 11.3 53.8
97 0.8 1.2 16.3
98 1.5 0.9 25.3
99 1.2 22.4 78.2
Mean Q Time Cubicle nurse_queue_longer
Run Number
0 0.4 True
1 2.1 True
2 0.0 True
3 7.8 True
4 33.7 False
... ... ...
95 51.0 False
96 11.3 True
97 0.0 True
98 0.4 True
99 26.7 False
[100 rows x 5 columns]
Queue for nurse was longer than queue for cubicle in 54 trials of 10021.3.1 Exploring the number of cubicles
Let’s tweak our output to see the impact of changing the number of cubicles while keeping the number of receptionists, nurses and doctors consistent.
# Class representing a Trial for our simulation - a batch of simulation runs.
class Trial:
# The constructor sets up a pandas dataframe that will store the key
# results from each run against run number, with run number as the index.
def __init__(self):
self.df_trial_results = pd.DataFrame()
self.df_trial_results["Run Number"] = [0]
self.df_trial_results["Mean Q Time Recep"] = [0.0]
self.df_trial_results["Mean Q Time Nurse"] = [0.0]
self.df_trial_results["Mean Q Time Doctor"] = [0.0]
self.df_trial_results["Mean Q Time Cubicle"] = [0.0]
self.df_trial_results.set_index("Run Number", inplace=True)
# Method to print out the results from the trial. In real world models,
# you'd likely save them as well as (or instead of) printing them
def print_trial_results(self):
print ("Trial Results")
print (self.df_trial_results.round(1)) ##EDITED: Added rounding
# Method to run a trial
def run_trial(self):
# Run the simulation for the number of runs specified in g class.
# For each run, we create a new instance of the Model class and call its
# run method, which sets everything else in motion. Once the run has
# completed, we grab out the stored run results (just mean queuing time
# here) and store it against the run number in the trial results
# dataframe.
for run in range(g.number_of_runs):
random.seed(run)
my_model = Model(run)
my_model.run()
self.df_trial_results.loc[run] = [my_model.mean_q_time_recep,
my_model.mean_q_time_nurse,
my_model.mean_q_time_doctor,
my_model.mean_q_time_cubicle
]
# Once the trial (ie all runs) has completed, add an additional column
self.df_trial_results['nurse_queue_longer'] = np.where(self.df_trial_results['Mean Q Time Nurse'] > self.df_trial_results['Mean Q Time Cubicle'], True, False)
return (sum(self.df_trial_results['nurse_queue_longer'].values) / g.number_of_runs) ##NEWresults = []
for num_cubicles in range(1, 20, 1):
g.number_of_cubicles = num_cubicles
# Create an instance of the Trial class
my_trial = Trial()
# Call the run_trial method of our Trial object
trial_results = my_trial.run_trial()
results.append({"Number of cubicles": num_cubicles,
"% of Trials with longer nurse queue time than cubicle queue time": trial_results})
results_df = pd.DataFrame(results)
results_df| Number of cubicles | % of Trials with longer nurse queue time than cubicle queue time | |
|---|---|---|
| 0 | 1 | 0.00 |
| 1 | 2 | 0.00 |
| 2 | 3 | 0.00 |
| 3 | 4 | 0.00 |
| 4 | 5 | 0.03 |
| 5 | 6 | 0.09 |
| 6 | 7 | 0.18 |
| 7 | 8 | 0.29 |
| 8 | 9 | 0.35 |
| 9 | 10 | 0.40 |
| 10 | 11 | 0.46 |
| 11 | 12 | 0.54 |
| 12 | 13 | 0.62 |
| 13 | 14 | 0.68 |
| 14 | 15 | 0.72 |
| 15 | 16 | 0.75 |
| 16 | 17 | 0.71 |
| 17 | 18 | 0.78 |
| 18 | 19 | 0.81 |
import plotly.express as px
px.line(
results_df,
x="Number of cubicles",
y="% of Trials with longer nurse queue time than cubicle queue time",
title=f"Impact of cubicle numbers with {g.number_of_nurses} nurses"
)Now, our rate limiting step might actually be the number of doctors, as their consultations take longer on average (20 minutes on average with roughly 60% of patients needing to see a doctor after seeing the nurse; nurse consults take on average 6 minutes but every patient sees a nurse). Let’s fix the number of cubicles at 8 and look at the impact of changing the number of doctors instead.
g.number_of_cubicles = 8
results = []
for num_doctors in range(1, 20, 1):
g.number_of_doctors = num_doctors
# Create an instance of the Trial class
my_trial = Trial()
# Call the run_trial method of our Trial object
trial_results = my_trial.run_trial()
results.append({"Number of doctors": num_doctors,
"% of Trials with longer nurse queue time than cubicle queue time": trial_results})
results_df = pd.DataFrame(results)
results_df| Number of doctors | % of Trials with longer nurse queue time than cubicle queue time | |
|---|---|---|
| 0 | 1 | 0.00 |
| 1 | 2 | 0.29 |
| 2 | 3 | 0.87 |
| 3 | 4 | 1.00 |
| 4 | 5 | 1.00 |
| 5 | 6 | 1.00 |
| 6 | 7 | 1.00 |
| 7 | 8 | 1.00 |
| 8 | 9 | 1.00 |
| 9 | 10 | 1.00 |
| 10 | 11 | 1.00 |
| 11 | 12 | 1.00 |
| 12 | 13 | 1.00 |
| 13 | 14 | 1.00 |
| 14 | 15 | 1.00 |
| 15 | 16 | 1.00 |
| 16 | 17 | 1.00 |
| 17 | 18 | 1.00 |
| 18 | 19 | 1.00 |
px.line(
results_df,
x="Number of doctors",
y="% of Trials with longer nurse queue time than cubicle queue time",
title=f"Impact of doctor numbers with {g.number_of_nurses} nurses and {g.number_of_cubicles} cubicles"
)You can see that with more doctors we very quickly start to see the number of nurses being the rate limiting factor rather than the number of nurses.
Note
Take a look at the chapter “Testing Large Numbers of Scenarios” (Chapter 26) to see how you could automatically try out different combinations of nurse, doctor and cubicle numbers to find the optiumum value.